ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
最近,我给我的网站(https://www.xiandanplay.com/)尝试集成了一下es来实现我的一个搜索功能,因为这个是我第一次了解运用elastic,所以如果有不对的地方,大家可以指出来,话不多说,先看看我的一个大致流程
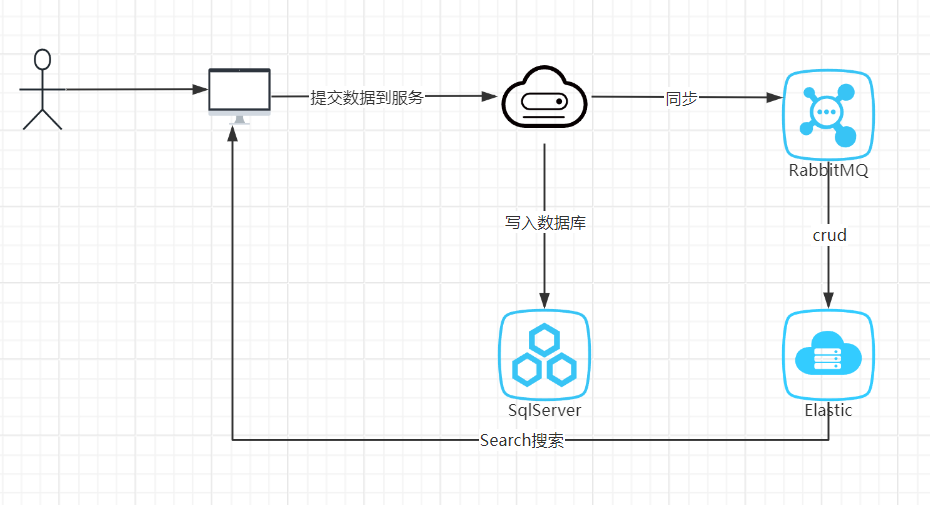
这里我采用的sdk的版本是Elastic.Clients.Elasticsearch, Version=8.0.0.0,官方的网址Installation | Elasticsearch .NET Client [8.0] | Elastic
我的es最开始打算和我的应用程序一起部署到ubuntu上面,结果最后安装kibana的时候,各种问题,虽好无奈,只好和我的SqlServer一起安装到windows上面,对于一个2G内容的服务器来说,属实有点遭罪了。
1、配置es
在es里面,我开启了密码认证。下面是我的配置
"Search": { "IsEnable": "true", "Uri": "http://127.0.0.1:9200/", "User": "123", "Password": "123" }
然后新增一个程序集
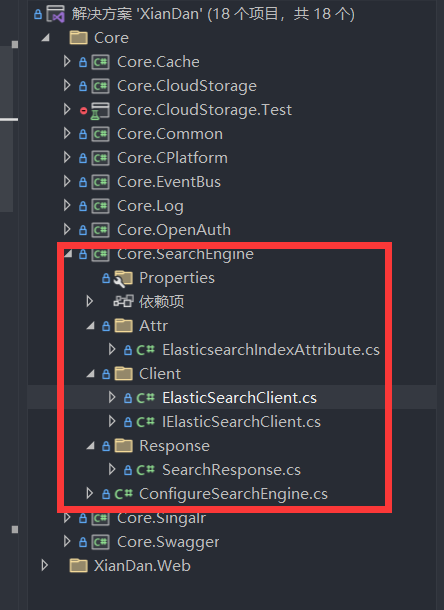
然后再ElasticsearchClient里面去写一个构造函数去配置es
using Core.Common;
using Core.CPlatform;
using Core.SearchEngine.Attr;
using Elastic.Clients.Elasticsearch;
using Elastic.Clients.Elasticsearch.IndexManagement;
using Elastic.Transport;
namespace Core.SearchEngine.Client
{
public class ElasticSearchClient : IElasticSearchClient
{
private ElasticsearchClient elasticsearchClient;
public ElasticSearchClient()
{
string uri = ConfigureProvider.configuration.GetSection("Search:Uri").Value;
string username = ConfigureProvider.configuration.GetSection("Search:User").Value;
string password = ConfigureProvider.configuration.GetSection("Search:Password").Value;
var settings = new ElasticsearchClientSettings(new Uri(uri))
.Authentication(new BasicAuthentication(username, password)).DisableDirectStreaming();
elasticsearchClient = new ElasticsearchClient(settings);
}
public ElasticsearchClient GetClient()
{
return elasticsearchClient;
}
}
}
然后,我们看skd的官网有这个这个提示
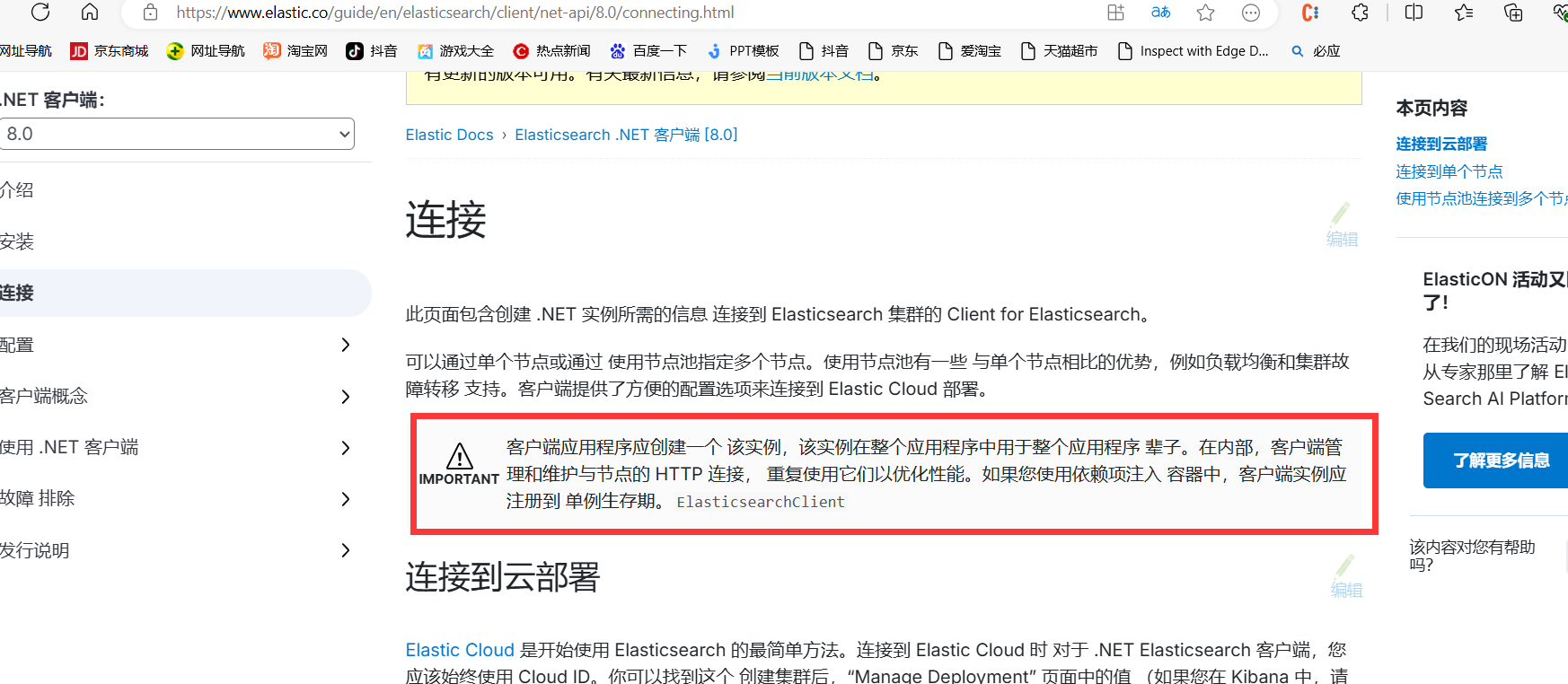
客户端应用程序应创建一个 该实例,该实例在整个应用程序中用于整个应用程序 辈子。在内部,客户端管理和维护与节点的 HTTP 连接, 重复使用它们以优化性能。如果您使用依赖项注入 容器中,客户端实例应注册到 单例生存期
所以我直接给它来一个AddSingleton
using Core.SearchEngine.Client; using Microsoft.Extensions.DependencyInjection; namespace Core.SearchEngine { public static class ConfigureSearchEngine { public static void AddSearchEngine(this IServiceCollection services) { services.AddSingleton<IElasticSearchClient, ElasticSearchClient>(); } } }
2、提交文章并且同步到es
然后就是同步文章到es了,我是先写入数据库,再同步到rabbitmq,通过事件总线(基于事件总线EventBus实现邮件推送功能)写入到es
先定义一个es模型
using Core.SearchEngine.Attr; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using XianDan.Model.BizEnum; namespace XianDan.Domain.Article { [ElasticsearchIndex(IndexName ="t_article")]//自定义的特性,sdk并不包含这个特性 public class Article_ES { public long Id { get; set; } /// <summary> /// 作者 /// </summary> public string Author { get; set; } /// <summary> /// 标题 /// </summary> public string Title { get; set; } /// <summary> /// 标签 /// </summary> public string Tag { get; set; } /// <summary> /// 简介 /// </summary> public string Description { get; set; } /// <summary> /// 内容 /// </summary> public string ArticleContent { get; set; } /// <summary> /// 专栏 /// </summary> public long ArticleCategoryId { get; set; } /// <summary> /// 是否原创 /// </summary> public bool? IsOriginal { get; set; } /// <summary> /// 评论数 /// </summary> public int? CommentCount { get; set; } /// <summary> /// 点赞数 /// </summary> public int? PraiseCount { get; set; } /// <summary> /// 浏览次数 /// </summary> public int? BrowserCount { get; set; } /// <summary> /// 收藏数量 /// </summary> public int? CollectCount { get; set; } /// <summary> /// 创建时间 /// </summary> public DateTime CreateTime { get; set; } } }
然后创建索引
string index = esArticleClient.GetIndexName(typeof(Article_ES)); await esArticleClient.GetClient().Indices.CreateAsync<Article_ES>(index, s => s.Mappings( x => x.Properties( t => t.LongNumber(l => l.Id) .Text(l=>l.Title,z=>z.Analyzer(ik_max_word)) .Keyword(l=>l.Author) .Text(l=>l.Tag,z=>z.Analyzer(ik_max_word)) .Text(l=>l.Description,z=>z.Analyzer(ik_max_word)) .Text(l=>l.ArticleContent,z=>z.Analyzer(ik_max_word)) .LongNumber(l=>l.ArticleCategoryId) .Boolean(l=>l.IsOriginal) .IntegerNumber(l=>l.BrowserCount) .IntegerNumber(l=>l.PraiseCount) .IntegerNumber(l=>l.PraiseCount) .IntegerNumber(l=>l.CollectCount) .IntegerNumber(l=>l.CommentCount) .Date(l=>l.CreateTime) ) ) );
然后每次增删改文章的时候写入到mq,例如
private async Task SendToMq(Article article, Operation operation) { ArticleEventData articleEventData = new ArticleEventData(); articleEventData.Operation = operation; articleEventData.Article_ES = MapperUtil.Map<Article, Article_ES>(article); TaskRecord taskRecord = new TaskRecord(); taskRecord.Id = CreateEntityId(); taskRecord.TaskType = TaskRecordType.MQ; taskRecord.TaskName = "发送文章"; taskRecord.TaskStartTime = DateTime.Now; taskRecord.TaskStatu = (int)MqMessageStatu.New; articleEventData.Unique = taskRecord.Id.ToString(); taskRecord.TaskValue = JsonConvert.SerializeObject(articleEventData); await unitOfWork.GetRepository<TaskRecord>().InsertAsync(taskRecord); await unitOfWork.CommitAsync(); try { eventBus.Publish(GetMqExchangeName(), ExchangeType.Direct, BizKey.ArticleQueueName, articleEventData); } catch (Exception ex) { var taskRecordRepository = unitOfWork.GetRepository<TaskRecord>(); TaskRecord update = await taskRecordRepository.SelectByIdAsync(taskRecord.Id); update.TaskStatu = (int)MqMessageStatu.Fail; update.LastUpdateTime = DateTime.Now; update.TaskResult = "发送失败"; update.AdditionalData = ex.Message; await taskRecordRepository.UpdateAsync(update); await unitOfWork.CommitAsync(); } }
mq订阅之后写入es,具体的增删改的方法就不写了吧
3、开始查询es
等待写入文章之后,开始查询文章,这里sdk提供的查询的方法比较复杂,全都是通过lmbda一个个链式去拼接的,但是我又没有找到更好的方法,所以就先这样吧
先创建一个集合存放查询的表达式
List<Action<QueryDescriptor<Article_ES>>> querys = new List<Action<QueryDescriptor<Article_ES>>>();
然后定义一个几个需要查询的字段
我这里使用MultiMatch来实现多个字段匹配同一个查询条件,并且指定使用ik_smart分词
Field[] fields = { new Field("title"), new Field("tag"), new Field("articleContent"), new Field("description") }; querys.Add(s => s.MultiMatch(y => y.Fields(Fields.FromFields(fields)).Analyzer(ik_smart).Query(keyword).Type(TextQueryType.MostFields)));
定义查询结果高亮,给查询出来的匹配到的分词的字段添加标签,同时前端需要对这个样式处理,
Dictionary<Field, HighlightField> highlightFields = new Dictionary<Field, HighlightField>(); highlightFields.Add(new Field("title"), new HighlightField() { PreTags = new List<string> { "<em>" }, PostTags = new List<string> { "</em>" }, }); highlightFields.Add(new Field("description"), new HighlightField() { PreTags = new List<string> { "<em>" }, PostTags = new List<string> { "</em>" }, }); Highlight highlight = new Highlight() { Fields = highlightFields };
为了提高查询的效率,我只查部分的字段
SourceFilter sourceFilter = new SourceFilter(); sourceFilter.Includes = Fields.FromFields(new Field[] { "title", "id", "author", "description", "createTime", "browserCount", "commentCount" }); SourceConfig sourceConfig = new SourceConfig(sourceFilter); Action<SearchRequestDescriptor<Article_ES>> configureRequest = s => s.Index(index) .From((homeArticleCondition.CurrentPage - 1) * homeArticleCondition.PageSize) .Size(homeArticleCondition.PageSize) .Query(x => x.Bool(y => y.Must(querys.ToArray()))) .Source(sourceConfig) .Sort(y => y.Field(ht => ht.CreateTime, new FieldSort() { Order=SortOrder.Desc}))
获取查询的分词结果
var analyzeIndexRequest = new AnalyzeIndexRequest { Text = new string[] { keyword }, Analyzer = analyzer }; var analyzeResponse = await elasticsearchClient.Indices.AnalyzeAsync(analyzeIndexRequest); if (analyzeResponse.Tokens == null) return new string[0]; return analyzeResponse.Tokens.Select(s => s.Token).ToArray();
到此,这个就是大致的查询结果,完整的如下
public async Task<Core.SearchEngine.Response.SearchResponse<Article_ES>> SelectArticle(HomeArticleCondition homeArticleCondition) { string keyword = homeArticleCondition.Keyword.Trim(); bool isNumber = Regex.IsMatch(keyword, RegexPattern.IsNumberPattern); List<Action<QueryDescriptor<Article_ES>>> querys = new List<Action<QueryDescriptor<Article_ES>>>(); if (isNumber) { querys.Add(s => s.Bool(x => x.Should( should => should.Term(f => f.Field(z => z.Title).Value(keyword)) , should => should.Term(f => f.Field(z => z.Tag).Value(keyword)) , should => should.Term(f => f.Field(z => z.ArticleContent).Value(keyword)) ))); } else { Field[] fields = { new Field("title"), new Field("tag"), new Field("articleContent"), new Field("description") }; querys.Add(s => s.MultiMatch(y => y.Fields(Fields.FromFields(fields)).Analyzer(ik_smart).Query(keyword).Type(TextQueryType.MostFields))); } if (homeArticleCondition.ArticleCategoryId.HasValue) { querys.Add(s => s.Term(t => t.Field(f => f.ArticleCategoryId).Value(FieldValue.Long(homeArticleCondition.ArticleCategoryId.Value)))); } string index = esArticleClient.GetIndexName(typeof(Article_ES)); Dictionary<Field, HighlightField> highlightFields = new Dictionary<Field, HighlightField>(); highlightFields.Add(new Field("title"), new HighlightField() { PreTags = new List<string> { "<em>" }, PostTags = new List<string> { "</em>" }, }); highlightFields.Add(new Field("description"), new HighlightField() { PreTags = new List<string> { "<em>" }, PostTags = new List<string> { "</em>" }, }); Highlight highlight = new Highlight() { Fields = highlightFields }; SourceFilter sourceFilter = new SourceFilter(); sourceFilter.Includes = Fields.FromFields(new Field[] { "title", "id", "author", "description", "createTime", "browserCount", "commentCount" }); SourceConfig sourceConfig = new SourceConfig(sourceFilter); Action<SearchRequestDescriptor<Article_ES>> configureRequest = s => s.Index(index) .From((homeArticleCondition.CurrentPage - 1) * homeArticleCondition.PageSize) .Size(homeArticleCondition.PageSize) .Query(x => x.Bool(y => y.Must(querys.ToArray()))) .Source(sourceConfig) .Sort(y => y.Field(ht => ht.CreateTime, new FieldSort() { Order=SortOrder.Desc})).Highlight(highlight); var resp = await esArticleClient.GetClient().SearchAsync<Article_ES>(configureRequest); foreach (var item in resp.Hits) { if (item.Highlight == null) continue; foreach (var dict in item.Highlight) { switch (dict.Key) { case "title": item.Source.Title = string.Join("...", dict.Value); break; case "description": item.Source.Description = string.Join("...", dict.Value); break; } } } string[] analyzeWords = await esArticleClient.AnalyzeAsync(homeArticleCondition.Keyword); List<Article_ES> articles = resp.Documents.ToList(); return new Core.SearchEngine.Response.SearchResponse<Article_ES>(articles, analyzeWords); }
4、演示效果
搞完之后,发布部署,看看效果,分词这里要想做的像百度那样,估计目前来看非常有难度的
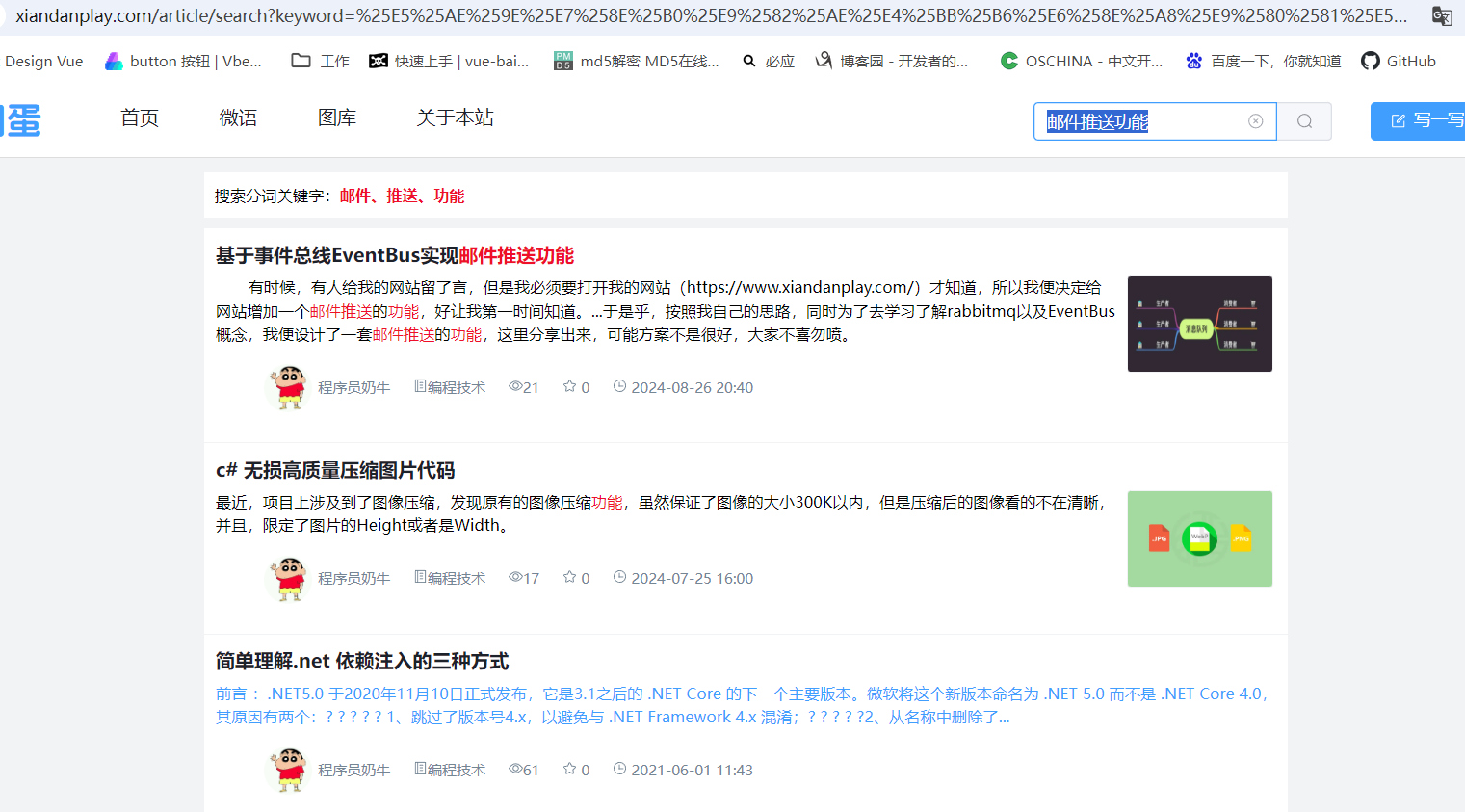
那么这里我也向大家求教一下,如何使用SearchRequest封装多个查询条件,如下
SearchRequest searchRequest = new SearchRequest();
searchRequest.From = 0;
searchRequest.Size = 10;
searchRequest.Query=多个查询条件
因为我觉得这样代码读起来比lambda可读性高些,能更好的动态封装。
 官方公众号
官方公众号