ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
1.首先在hadoop官网下载一个稳定版本,选择binary包
官网地址:https://hadoop.apache.org/releases.html
下载下来是tar.gz文件,用winrar解压即可。
2.因为这个压缩包是for linux系统的,win下还需要安装几个dll winutils,
下载地址:https://www.jianguoyun.com/p/Dcs2UoQQzuztCxiq89oFIAA
1.在环境变量中配置好JAVA_HOME
2.将压缩包解压到 D:\\hadoop-3.3.6\ ,并在环境变量里将此路径添加到 HADOOP_HOME。
3.将 hadoop-3.3.6 目录下的 bin 文件夹添加到 PATH 变量中。
4.并把 winutils 压缩包解压后的 dll 文件拷贝复制到 hadoop 的 bin 目录下。
1.配置 hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///D:/hadoop-3.3.6/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///D:/hadoop-3.3.6/data/datanode</value> </property> </configuration>
2.配置 core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://127.0.0.1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/D:\\hadoop-3.3.6\data\tmp</value> </property> </configuration>
3.配置 mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>hdfs://localhost:9001</value> </property> </configuration>
4.配置 yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hahoop.mapred.ShuffleHandler</value> </property> </configuration>
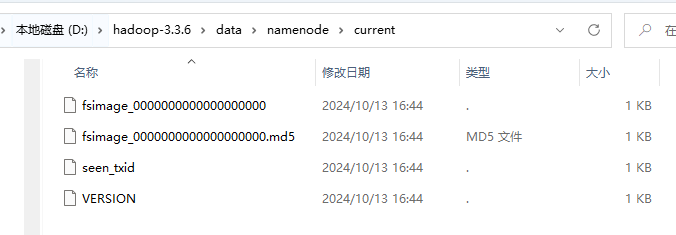
1.执行 hdfs namenode -format 命令, 初始化数据目录
成功后会生成如下文件
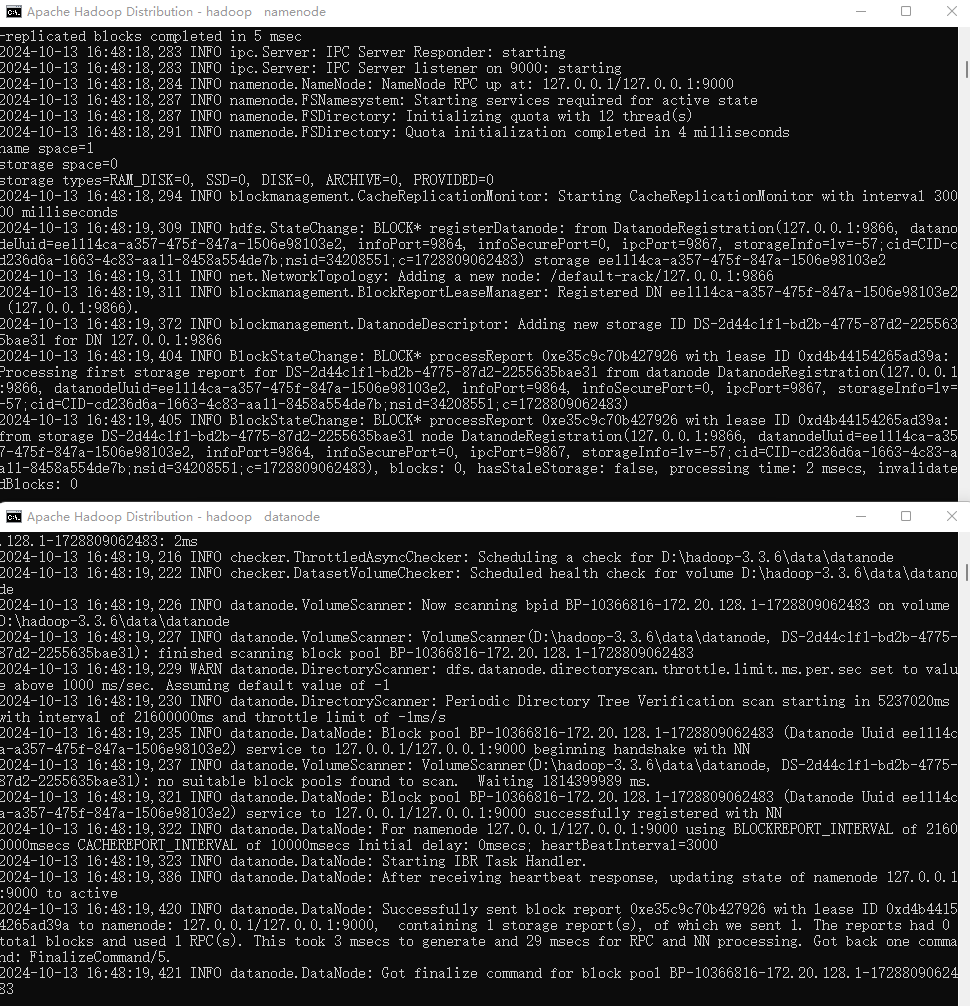
2.执行 start-dfs.cmd , 启动 namenode 和 datanode 进程
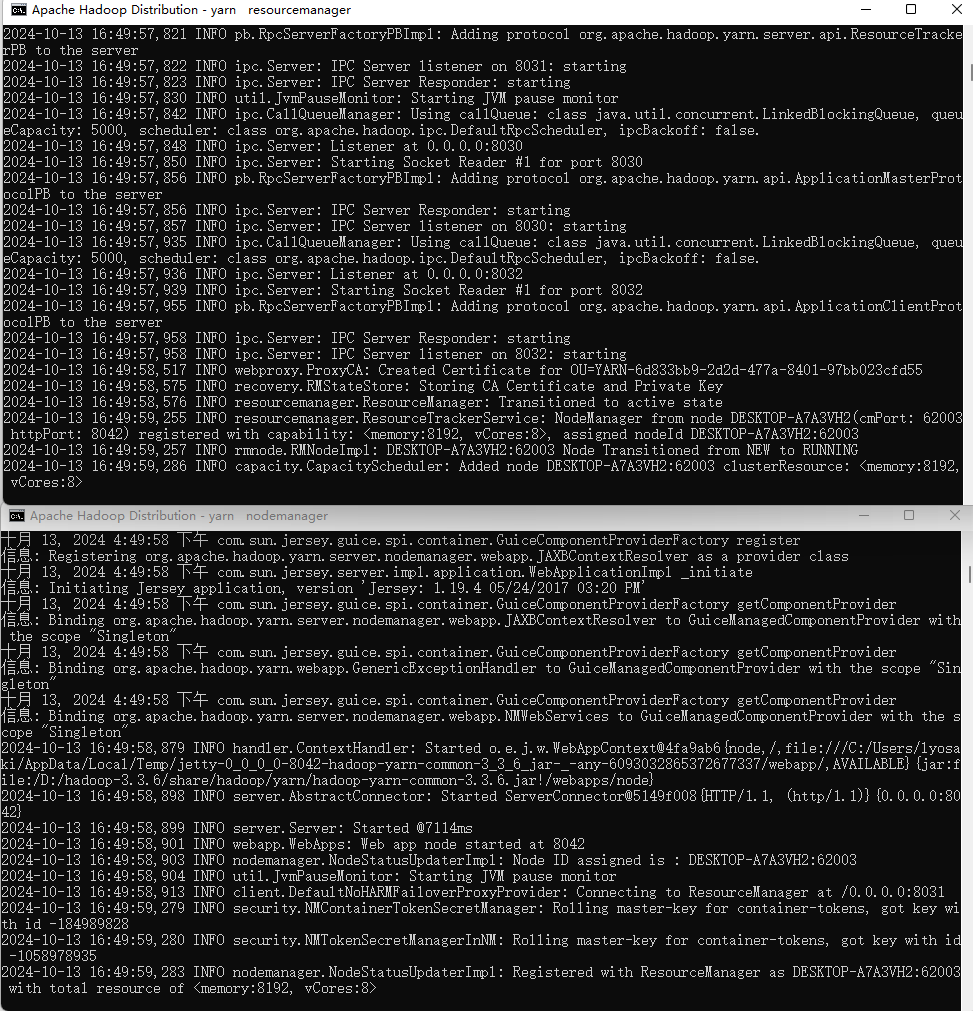
3.执行 start-yarn.cmd , 启动 resourcemanager 和 nodemanager进程
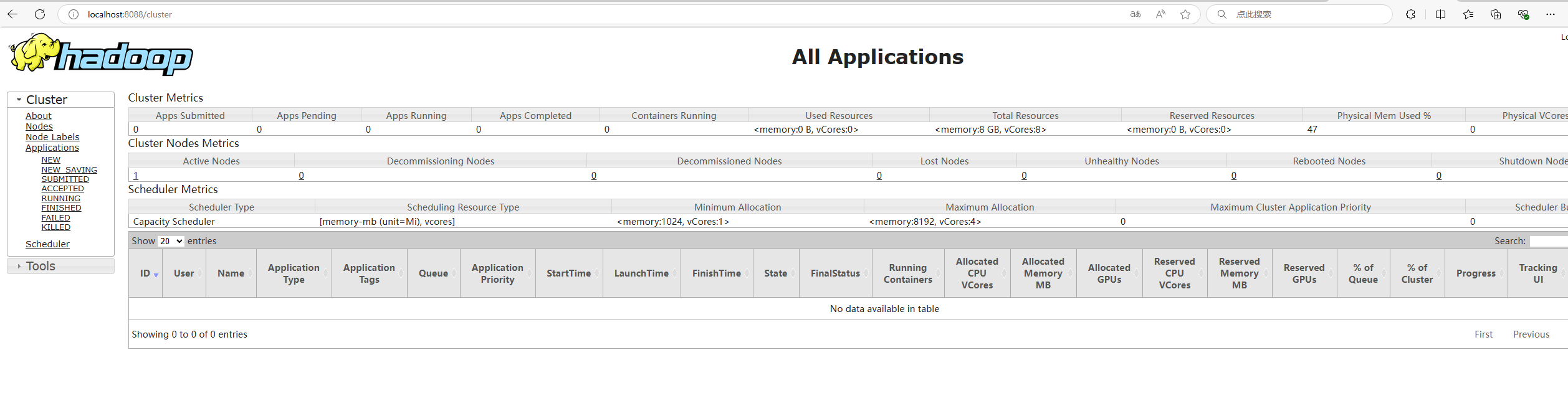
1.启动成功后, 访问 localhost:8088,可以看到 hadoop 的管理页面
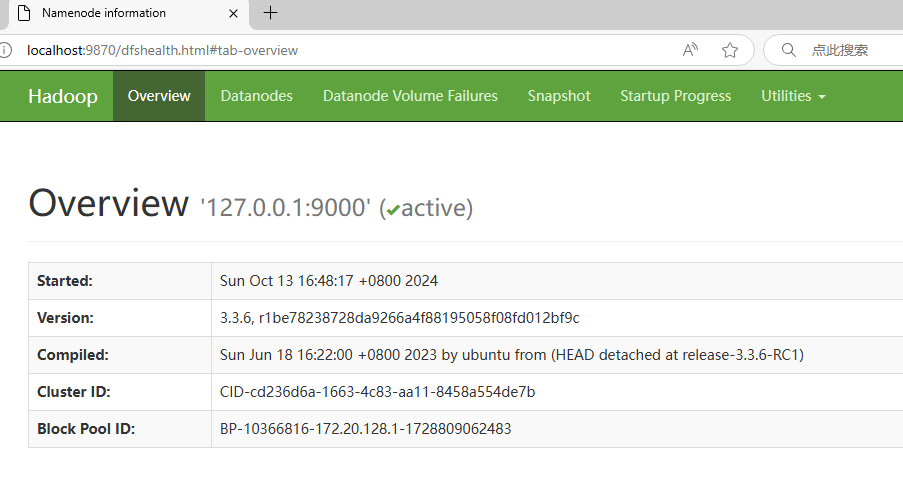
2. 访问 localhost:9870, 查看 namenode 节点的管理信息
 官方公众号
官方公众号