ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
布隆过滤器(Bloom Filter)是一种空间效率极高的数据结构,用于快速判断一个元素是否在集合中。它能够节省大量内存,但它有一个特点:可能存在误判,即可能会认为某个元素存在于集合中,但实际上不存在;而对于不存在的元素,它保证一定不会误判。布隆过滤器适合在对存储空间要求极为严格,同时能接受少量误判的应用场景中使用。
布隆过滤器的核心思想是使用多个哈希函数(Hash Functions)和一个位数组(Bit Array)。其操作过程如下:
1。1。1,则布隆过滤器认为这个元素可能存在;如果任意一个位置的位为 0,则可以确定这个元素一定不存在。1,而误认为这个元素存在。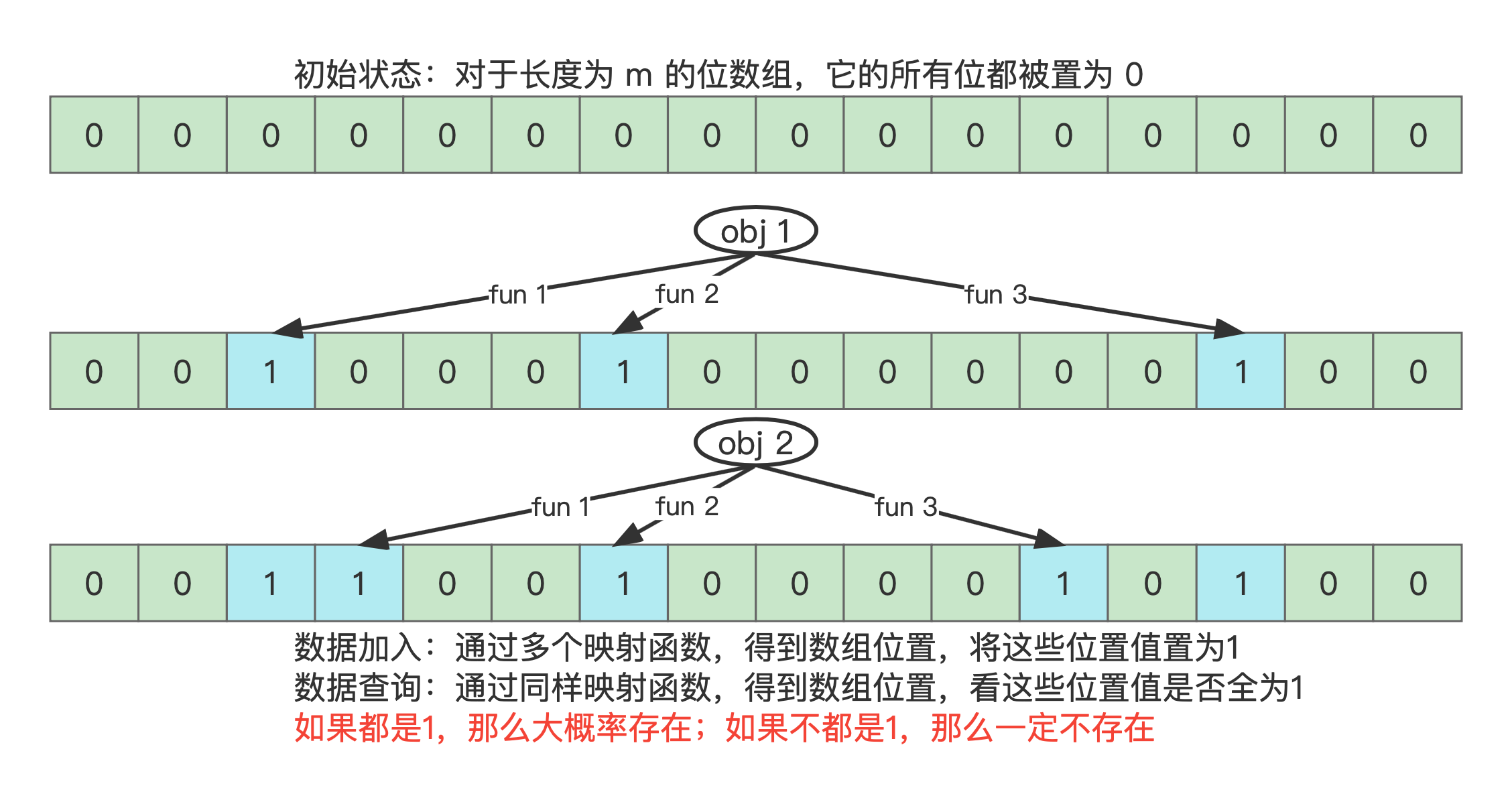
位数组是布隆过滤器的核心数据结构。它是一个长度为 m 的数组,每个位置上只能存储 0 或 1。初始时,位数组中所有位置的值都为 0。在插入元素时,哈希函数根据元素值生成若干个位置索引,并将这些索引对应的位设为 1。
布隆过滤器使用多个哈希函数(通常是独立的哈希函数)来对元素进行哈希操作。每个哈希函数会生成一个不同的位数组索引,用于确定元素的存储位置。
k 表示用于每个元素的哈希函数的个数。哈希函数数量越多,误判的概率越低,但查询和插入的复杂度会增加。因此,k 的数量一般选择一个合适的中间值,以在查询性能和误判率之间取得平衡。
m 是位数组的长度,位数组越长,误判率越低,但需要占用的内存也更多。因此,位数组的长度应该根据实际的业务需求和内存开销进行权衡设计。
布隆过滤器的误判率是指在查询时,布隆过滤器错误地认为一个不存在的元素存在于集合中的概率。误判率随着集合中插入的元素数量的增加而增加,主要受到以下几个因素的影响:
1 的位越来越多,哈希函数的碰撞机会增大。布隆过滤器的误判率计算公式如下: p=(1−e−k⋅nm)kp = \left( 1 - e^{- \frac{k \cdot n}{m}} \right)^kp=(1−e−mk⋅n)k
p 是误判率;k 是哈希函数的数量;n 是插入的元素数量;m 是位数组的长度。布隆过滤器最常见的应用之一就是防止
缓存穿透
。在 Redis 缓存场景中,用户请求的数据可能在缓存和数据库中都不存在,如果不加以防护,这些请求会直接打到数据库。通过布隆过滤器,可以在请求前判断元素是否可能存在于数据库中,从而减少无效的数据库查询。
计数布隆过滤器是一种支持删除操作的布隆过滤器。与标准布隆过滤器不同的是,计数布隆过滤器的位数组中的每个位置不再是二进制的 0 和 1,而是一个计数器。当插入一个元素时,多个哈希函数对应的位上的计数器增加;当删除一个元素时,计数器相应减少。
计数布隆过滤器的缺点是需要更多的存储空间(因为每个位置是一个计数器),但它允许删除元素,这使得它适用于动态更新的场景。
在大规模分布式系统中,布隆过滤器可以扩展为分布式布隆过滤器,即将位数组分布在多个节点上,并且每个节点负责一部分位数组的存储和哈希计算。这样可以提高系统的可扩展性,适应更大规模的数据集。
布隆过滤器是一种空间效率极高的数据结构,适用于需要快速判断某个元素是否存在的场景,尤其适用于防止缓存穿透、垃圾邮件过滤、大数据去重等场景。虽然它存在一定的误判率,但其出色的空间效率和查询性能使其成为许多大规模应用中的重要工具。
 官方公众号
官方公众号