ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
hdfs checkpoint 机制对于 namenode 元数据的保护至关重要, 是否正常完成检查点是评估 hdfs 集群健康度和风险的重要指标
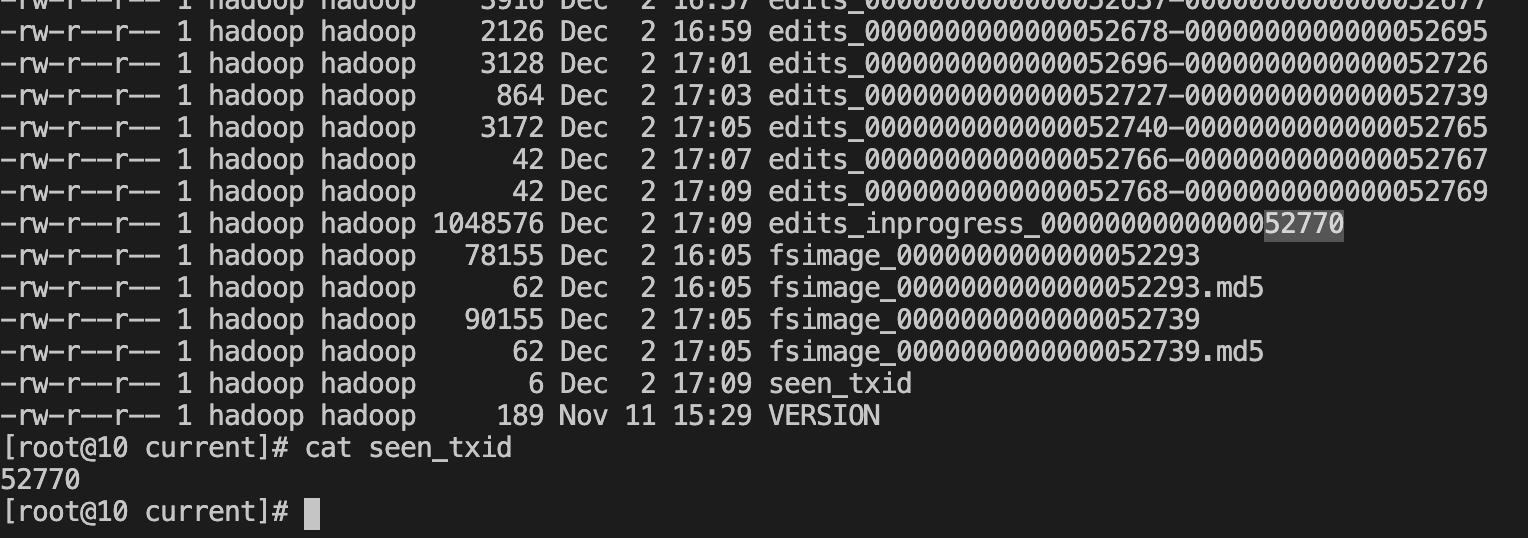
检查点将从旧的 fsimage 和编辑日志进行合并,创建一个新的 fsimage
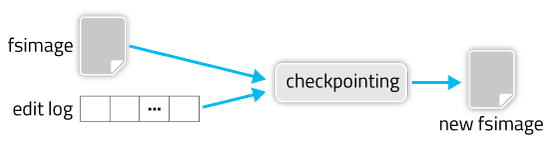
checkpoint 触发由三个参数控制
dfs.namenode.checkpoint.period
dfs.namenode.checkpoint.txns
dfs.namenode.checkpoint.check.period
这里 standby namenode 称为 SBNN,active namenode 称为 ANN
对于大规模的集群,如果长期未成功完成 checkpoint ,那么会积累非常多的 editlog 文件.重启 namenode 的时候,必须要回放 editlog ,以使内存中的目录树恢复到最新状态.回放 editlog 必然是逐个文件来回放的,此时如果积累了大量的 editlog 文件,那么这个过程会长达三个小时以上.增大 namenode 的内存可以适当加快这个过程.
如果长期 edit 日志文件有堆积,可以进入安全模式后,手动运行 saveNamespace 命令来进行一次合并. 但是线上环境中,不能进入安全模式,这个时候可以通过重启 standynamenode 来触发一次 checkpoint
遇到过一次线上问题,由于 ann 锁的问题导致 sbnn 无法 put fsimage 到 ann,重启 sbnn 也无法完成最终完成 checkpoint ,这个时候可以等 sbnn namespace 正常启动后,然后进行一次主备切换,使之前锁住的 ann 变成了 sbnn,然后重启这个节点,此时就能够完成 checkpoint 了,堆积的 edit 文件也能够被清理了
hdfs dfsadmin -fs 10.0.0.26:4007 -safemode enter
hdfs dfsadmin -fs 10.0.0.26:4007 -saveNamespace
hdfs dfsadmin -fs 10.0.0.26:4007 -safemode leave
hdfs dfsadmin -safemode forceExit //强制退出安全模式
有两个重要指标:
hdfs 在重启流程需要加载 edit logs,如果 edit logs 遗留有没被注意到的错误, hdfs 将会无法启动完成,导致生产事故
比较常见的原因是:
误删editslog、JournalNode节点有断电、数据目录磁盘占满、网络持续异常等
常见报错如下:
java.io.IOException: Gap in transactions. Expected to be able to read up until at least txid 813248390 but unable to find any edit logs containing txid 363417469可以动态开启DEBUG 日志级别定位报错位置
解决办法:
 官方公众号
官方公众号