ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
看到这个题目就知道上一节提到的RISC-V手册的10.6节又有用武之地了.
这里只需注意,RV32 的分页方案Sv32支持4GiB的虚址空间,RV64 支持多种分页方案,但我们只介绍最受欢迎的一种,Sv39。:
RISC-V 的分页方案以SvX的模式命名,其中X是以位为单位的虚拟地址的长度。
默认情况下是没有开启MMU的,此时无论CPU处于哪个特权级,访问内存的地址都是物理地址.
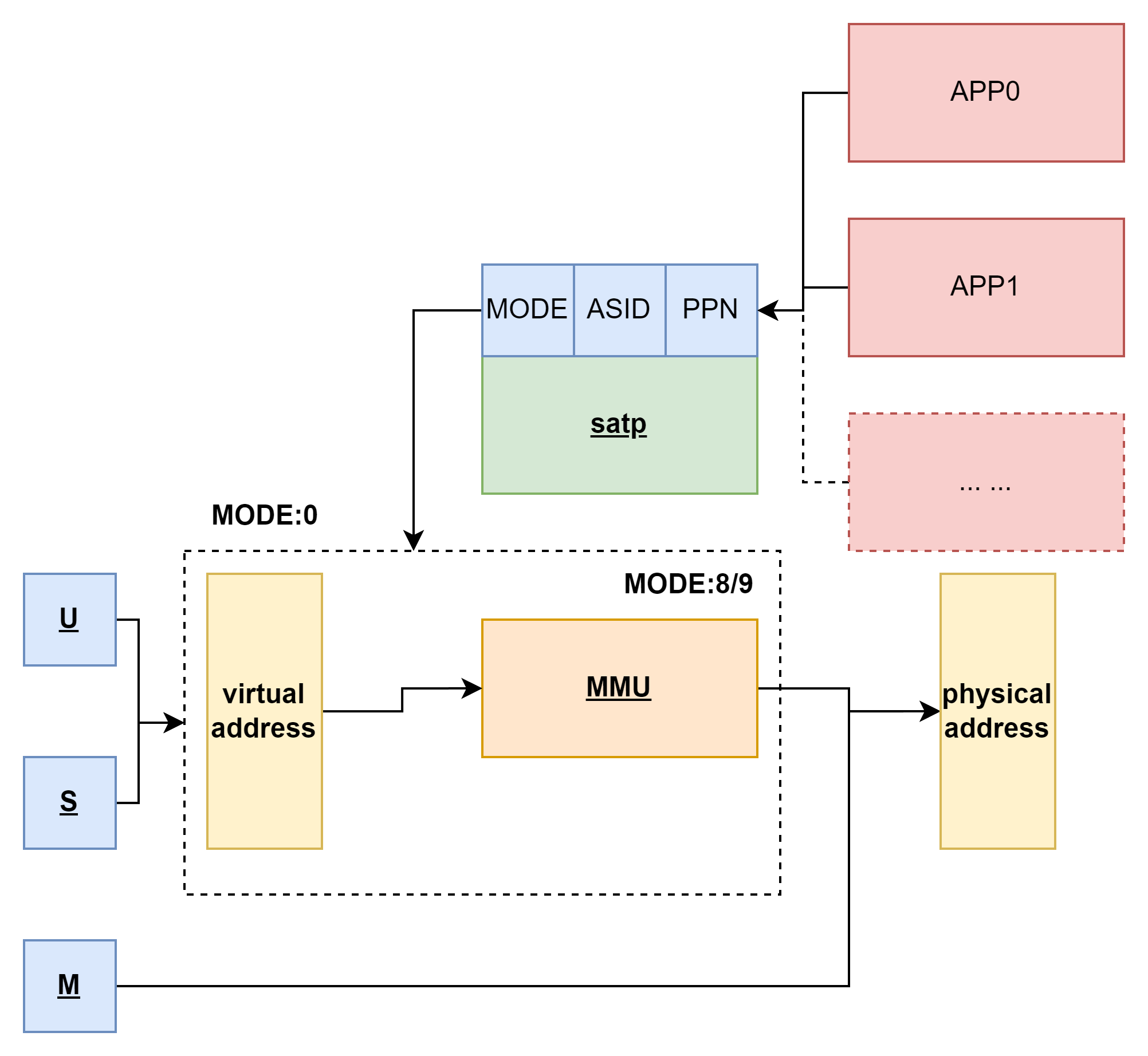
有一个CSR(Control and Status Register 控制状态寄存器),决定了MMU的控制.名叫satp(Supervisor Address Translation and Protection 监管地址翻译和保护寄存器).
其结构如图所示:

MODE 控制 CPU 使用哪种页表实现;
MODE为0---b0000的时候,所有的优先级的内存访问都是直接访问物理内存MODE设置为8---b1000时,分页机制被开启,而且选用的是SV39分页机制,那么S/U级别的特权级访问的时候就需要通过MMU.MODE设置为9---b1001时,分页机制被开启,而且选用的是SV48分页机制,这里不讨论这种分页机制.ASID 表示地址空间标识符,这里还没有涉及到进程的概念,我们不需要管这个地方.PPN 存的是根页表所在的物理页号.这样, 给定一个虚拟页号,CPU 就可以从三级页表的根页表开始一步步的将其映射到一个物理页号.这个PPN也很重要,虽然我们在这里只提到了有关于模式选择的MODE,但是到了后边真正要完成访存的时候PPN决定的根节点决定了我们当前不同APP同样的虚拟内存怎么映射到不同的物理内存的.
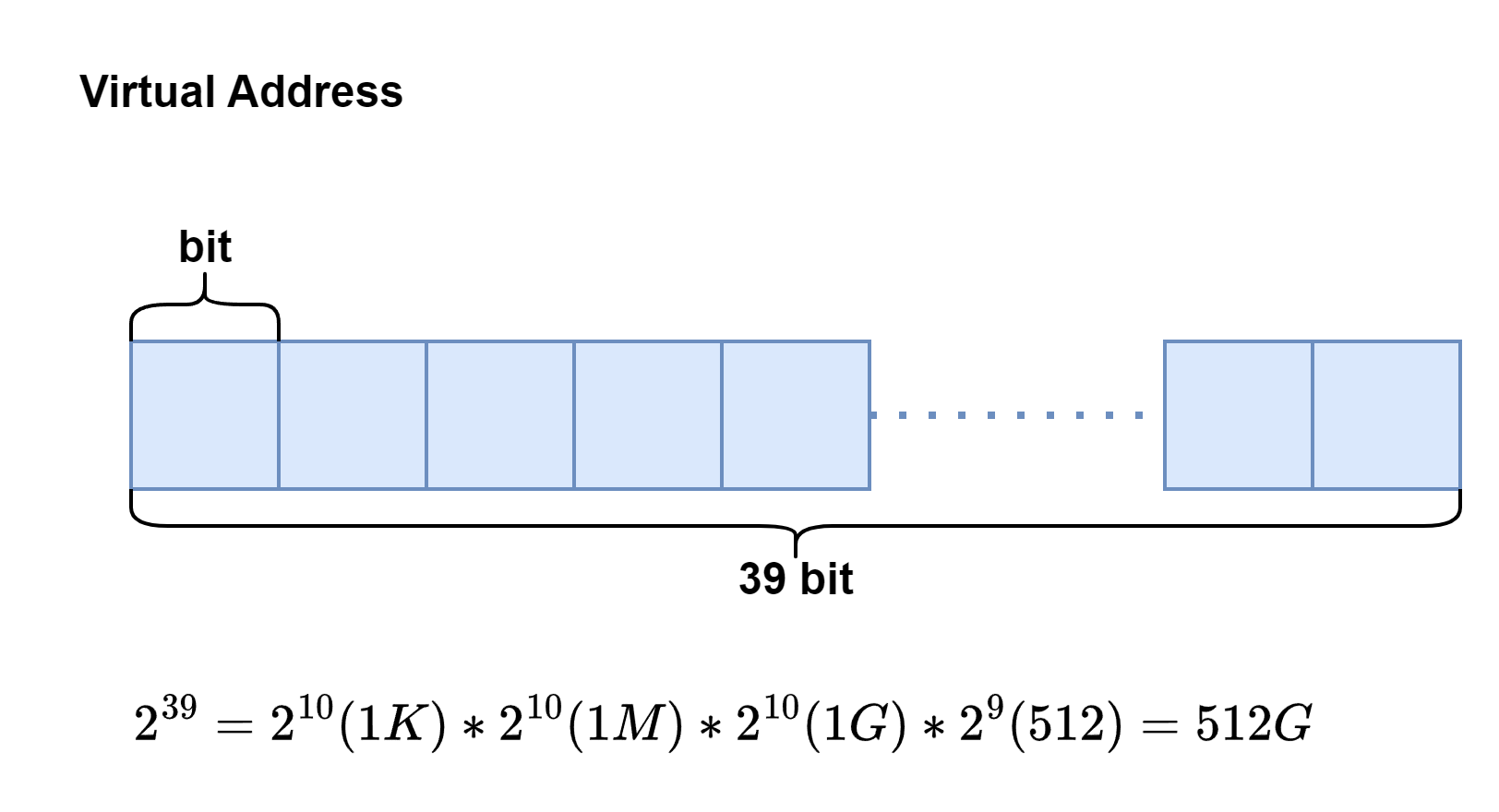
首先,我们只考虑虚拟地址和物理地址的位数,而不去考虑地址的每个位的作用.
那么39位的虚拟地址,最多可以访问高达512G的内存.
更甚的,拥有56位的物理地址,则能够访问更多大的内存范围(数据来自于GPT).
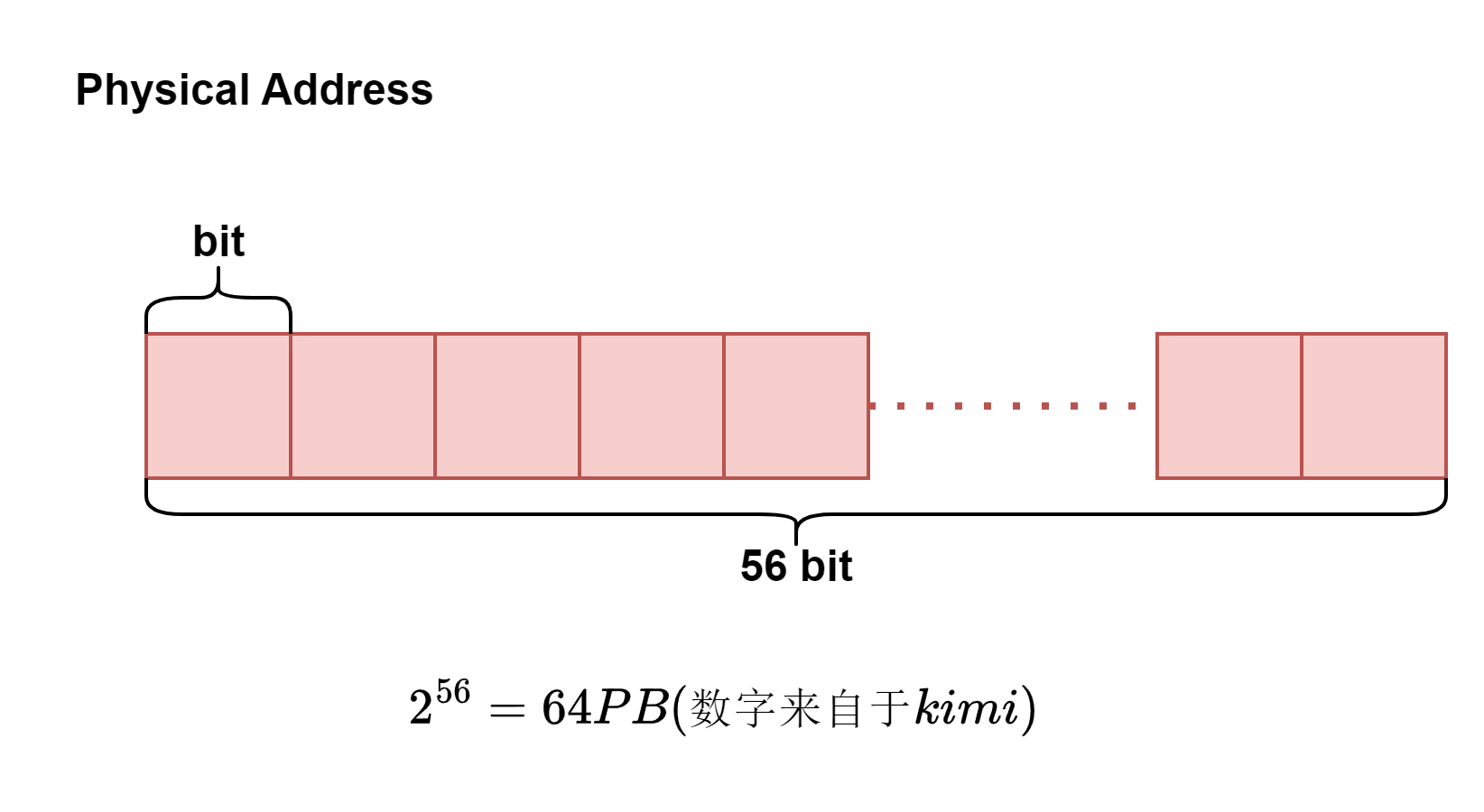
但是实际上讨论这个最大储存上限是没有意义的,这样的地址形式没办法产生虚拟地址和物理地址之间的映射,没有固定的映射那就更难通过MMU进行地址的转换.
那么我们实际上采用的是分页的储存方式,因此有一套属于分页储存的地址,如下图所示(图是偷的参考手册)的.

这个储存方式是偏移+页数的方式.
这里注意每个页面的大小设置为
4KiB.这个是我们自己设置的,对应的是offset是12bit,这样才能通过偏移来访问每个Byte.
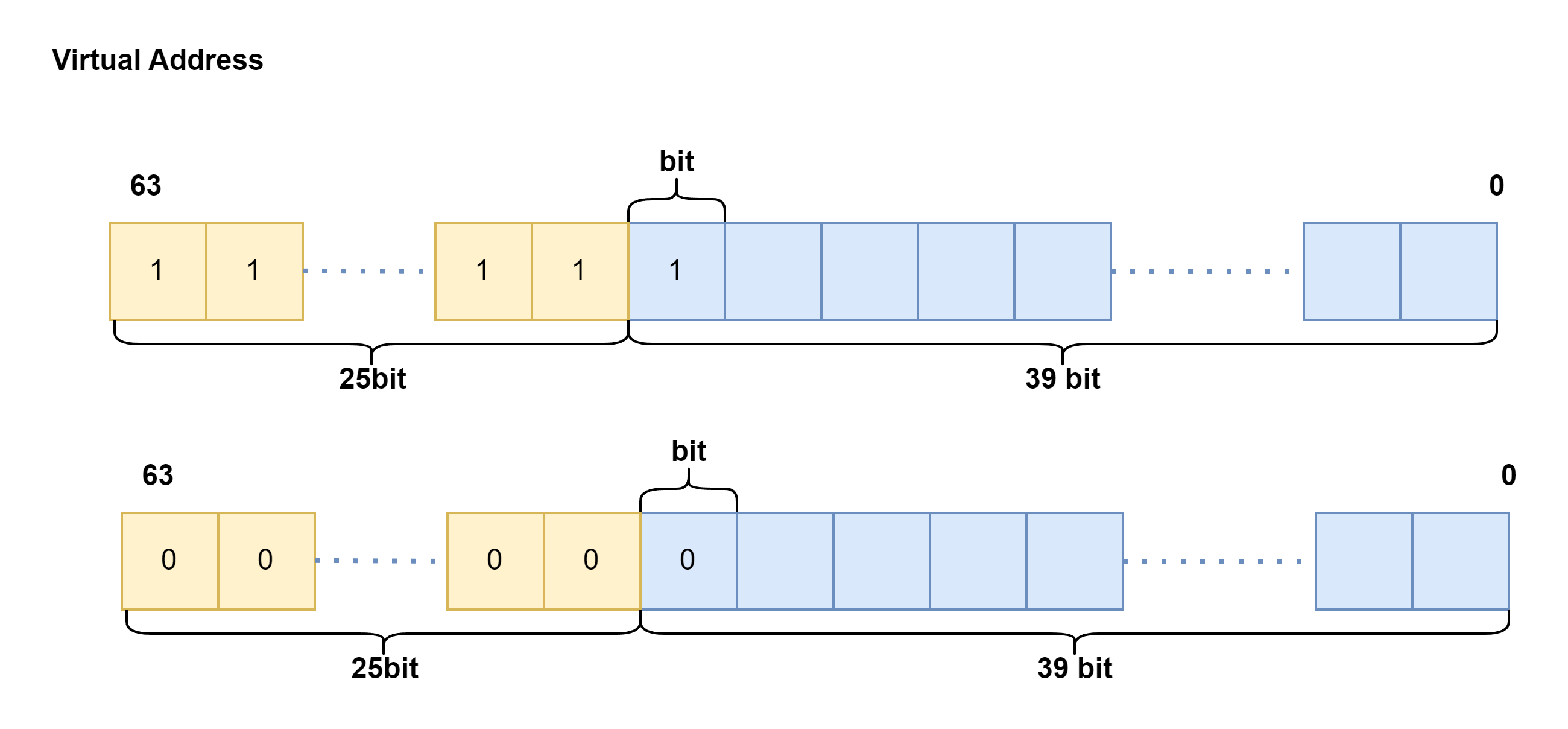
RISC-V要求地址长度为64位,这里我们只用到了39位,但是不代表前38位就完全没有要求.
在启用 SV39 分页模式下,只有低 39 位是真正有意义的。SV39 分页模式规定 64 位虚拟地址的 [63:39] 这 25 位必须和第 38 位相同,否则 MMU 会直接认定它是一个不合法的虚拟地址。通过这个检查之后 MMU 再取出低 39 位尝试将其转化为一个 56 位的物理地址。
那么就会有很神奇的事情发生,就是由于后边的[63:39]这部分都必须和第38位相同,那么就是都是1或者都是0,那么,实际上这0~38位代表的内存空间不是连续的一个512G,而是分为在地址最高的256G和地址最低的256G.
所需的数据结构:
这边使用的方式是使用一个元组式结构体.
// os/src/mm/address.rs
#[derive(Copy, Clone, Ord, PartialOrd, Eq, PartialEq)]
pub struct PhysAddr(pub usize);
#[derive(Copy, Clone, Ord, PartialOrd, Eq, PartialEq)]
pub struct VirtAddr(pub usize);
#[derive(Copy, Clone, Ord, PartialOrd, Eq, PartialEq)]
pub struct PhysPageNum(pub usize);
#[derive(Copy, Clone, Ord, PartialOrd, Eq, PartialEq)]
pub struct VirtPageNum(pub usize);
里边的usize就是STRUCT.0.
这里注意一点,就是使用#[derive(Trait)]自动实现的Trait,尤其是之前没怎么用过的Ord和PartialOrd:
Copy:这个 trait 表示类型的值可以被“复制”。拥有Copytrait 的类型可以被简单地赋值给另一个变量,而不会改变原始值。例如,基本的数值类型(如i32、f64)和元组(如果它们包含的所有类型都实现了Copy)都实现了Copy。这个 trait 不能手动实现,只能通过派生。Clone:这个 trait 允许一个值被显式地复制。与Copy不同,Clone需要显式的调用(例如,使用clone()方法)。Clonetrait 要求类型可以被复制,但不要求复制是无成本的。如果一个类型实现了Copy,它自动也实现了Clone,但反之则不一定。Ord:这个 trait 表示类型支持全序比较,即可以比较任意两个值并确定它们之间的顺序(小于、等于、大于)。这意味着类型必须实现PartialOrd和Eq。PartialOrd:这个 trait 允许对类型的值进行部分顺序比较。这意味着可以比较两个值,但可能会返回None,表示它们不可比较。大多数时候,如果类型可以完全排序,那么PartialOrd也会被实现。Eq:这个 trait 表示类型支持等价性比较,即可以比较两个值是否相等。Eq是PartialEq和Ord的基础,它要求类型可以比较相等性。PartialEq:这个 trait 允许对类型的值进行等价性比较,但可能会返回None,表示它们不可比较。大多数时候,如果类型可以完全比较,那么PartialEq也会被实现。
(此处的解释来自于Kimi)
那么这么封装的好处,实际上是加一层抽象,有的时候觉得没用的抽象实际上使用的时候是非常有好处的.
我们刻意将它们各自抽象出不同的类型而不是都使用与RISC-V 64硬件直接对应的 usize 基本类型,就是为了在 Rust 编译器的帮助下,通过多种方便且安全的 类型转换 (Type Conversion) 来构建页表。
// os/src/mm/address.rs
const PA_WIDTH_SV39: usize = 56;
const PPN_WIDTH_SV39: usize = PA_WIDTH_SV39 - PAGE_SIZE_BITS;
impl From<usize> for PhysAddr {
fn from(v: usize) -> Self { Self(v & ( (1 << PA_WIDTH_SV39) - 1 )) }
}
impl From<usize> for PhysPageNum {
fn from(v: usize) -> Self { Self(v & ( (1 << PPN_WIDTH_SV39) - 1 )) }
}
impl From<PhysAddr> for usize {
fn from(v: PhysAddr) -> Self { v.0 }
}
impl From<PhysPageNum> for usize {
fn from(v: PhysPageNum) -> Self { v.0 }
}
这里注意PAGE_SIZE_BITS是作为一个常数保存在config.rs里边.
//os/src/config.rs
//* Constants for mm *//
pub const PAGE_SIZE_BITS: usize = 12;
刚刚看到这里的时候就发现了一件事,那么地址是比页号要多一个offset信息的,如果直接进行转换,那么怎么才能不进行信息丢失呢?
这里仔细去看如下的代码,我们可以看到,如果只有PhysPageNum,那么把它转换为PhysAddr的时候默认offset是0,那么反过来PhysAddr转化为PhysPageNum的时候,需要去判断offset是不是0,如果offset不是0,那么报错.
// os/src/mm/address.rs
impl PhysAddr {
pub fn page_offset(&self) -> usize { self.0 & (PAGE_SIZE - 1) }
}
impl From<PhysAddr> for PhysPageNum {
fn from(v: PhysAddr) -> Self {
assert_eq!(v.page_offset(), 0);
v.floor()
}
}
impl From<PhysPageNum> for PhysAddr {
fn from(v: PhysPageNum) -> Self { Self(v.0 << PAGE_SIZE_BITS) }
}
同样地,PAGE_SIZE是一个常数,被保存在config.rs里:
//os/src/config.rs
//* Constants for mm *//
pub const PAGE_SIZE: usize = 4096;
其中,读取offset的方法page_offset的实现:
impl PhysAddr {
pub fn page_offset(&self) -> usize { self.0 & (PAGE_SIZE - 1) }
}
最后我们产生了一些其它的疑问,那么如果offset不是0,难道就不能进行转换了吗?答案是可以进行转换,但是不能经过隐式的转换,要通过显式的转换,即你要知道自己进行了带有四舍五入的取整.
// os/src/mm/address.rs
impl PhysAddr {
pub fn floor(&self) -> PhysPageNum { PhysPageNum(self.0 / PAGE_SIZE) }
pub fn ceil(&self) -> PhysPageNum { PhysPageNum((self.0 + PAGE_SIZE - 1) / PAGE_SIZE) }
}
其中floor是向下取整,ceil是向上取整.
这里实际上还是很难理解向上取整的意义,因为这个offset太过靠近下一页,所以干脆取下一页吗?
向上取整是取一页新的没有占用过的,向下取整是取当前页.
这里是参考书中为我们提到的有关于From和Into的表述:
当我们为
U实现了From<T>之后,Rust 会自动为T实现Into<U>Trait,因为它们两个本来就是在做相同的事情。因此我们只需相互实现From就可以相互From/Into了。
其余的部分我不细说,之说对于T,你直接调用它的into它是不知道的,有点类似于CPP里的自动类型auto,在编译器可以隐式推倒到你需要的到底是什么类型的时候,就可以自动帮你决定这一点.
页表项就是一个同时含有页号信息和标志位的数据结构.

页号信息相当于是一个字典,映射一个虚拟地址和一个物理地址.
标志位则各不相同:
除了
G外的上述位可以被操作系统设置,只有A位和D位会被处理器动态地直接设置为1,表示对应的页被访问过或修过( 注:A位和D位能否被处理器硬件直接修改,取决于处理器的具体实现)。
这时候要在rust中实现它,这时候使用的是用一个位代表一个FLAG的形式,rust提供了这样的一个包,名字叫做bitflags.
因此要:
Cargo.toml中声明依赖这个包.main.rs中声明使用这个包.在我写下这篇博客的时候bitflag的版本截止到2.6.0,可以通过查看相关网站看到最新版本和细节.
// os/Cargo.toml
[dependencies]
bitflags = "2.6.0"
在main.rs中加入:
extern crate bitflags;
创建os/src/mm/page_table.rs,实现这部分FLAG:
use bitflags::bitflags;
bitflags!{
pub struct PTEFlags: u8{
const V = 1<<0;
const R = 1<<1;
const W = 1<<2;
const X = 1<<3;
const U = 1<<4;
const G = 1<<5;
const A = 1<<6;
const D = 1<<7;
}
}
怎么解读它呢?这里只提供一个简单的例子,更详细的部分需要继续自主学习:
bitflags! {
struct FlagsType: u8 {
// -- Bits type
// --------- Flags type
const A = 1;
// ----- Flag
}
}
let flag = FlagsType::A;
// ---- Flags value
这里对应的四个部分:
Bits type意味着这个flag一共有多少位,对应一个相应位数的类型.FlagsType就是给这个这一组标志位取一个总的名字.Flag就是给作为标志位的某个位取得名字.Flags value意味着你可以使用FlagsType::Flag访问对应的标志位的值.那么这时候继续实现页表项:
// os/src/mm/page_table.rs
#[derive(Copy, Clone)]
#[repr(C)]
pub struct PageTableEntry {
pub bits: usize,
}
impl PageTableEntry {
pub fn new(ppn: PhysPageNum, flags: PTEFlags) -> Self {
PageTableEntry {
bits: ppn.0 << 10 | flags.bits as usize,
}
}
pub fn empty() -> Self {
PageTableEntry {
bits: 0,
}
}
pub fn ppn(&self) -> PhysPageNum {
(self.bits >> 10 & ((1usize << 44) - 1)).into()
}
pub fn flags(&self) -> PTEFlags {
PTEFlags::from_bits(self.bits as u8).unwrap()
}
}
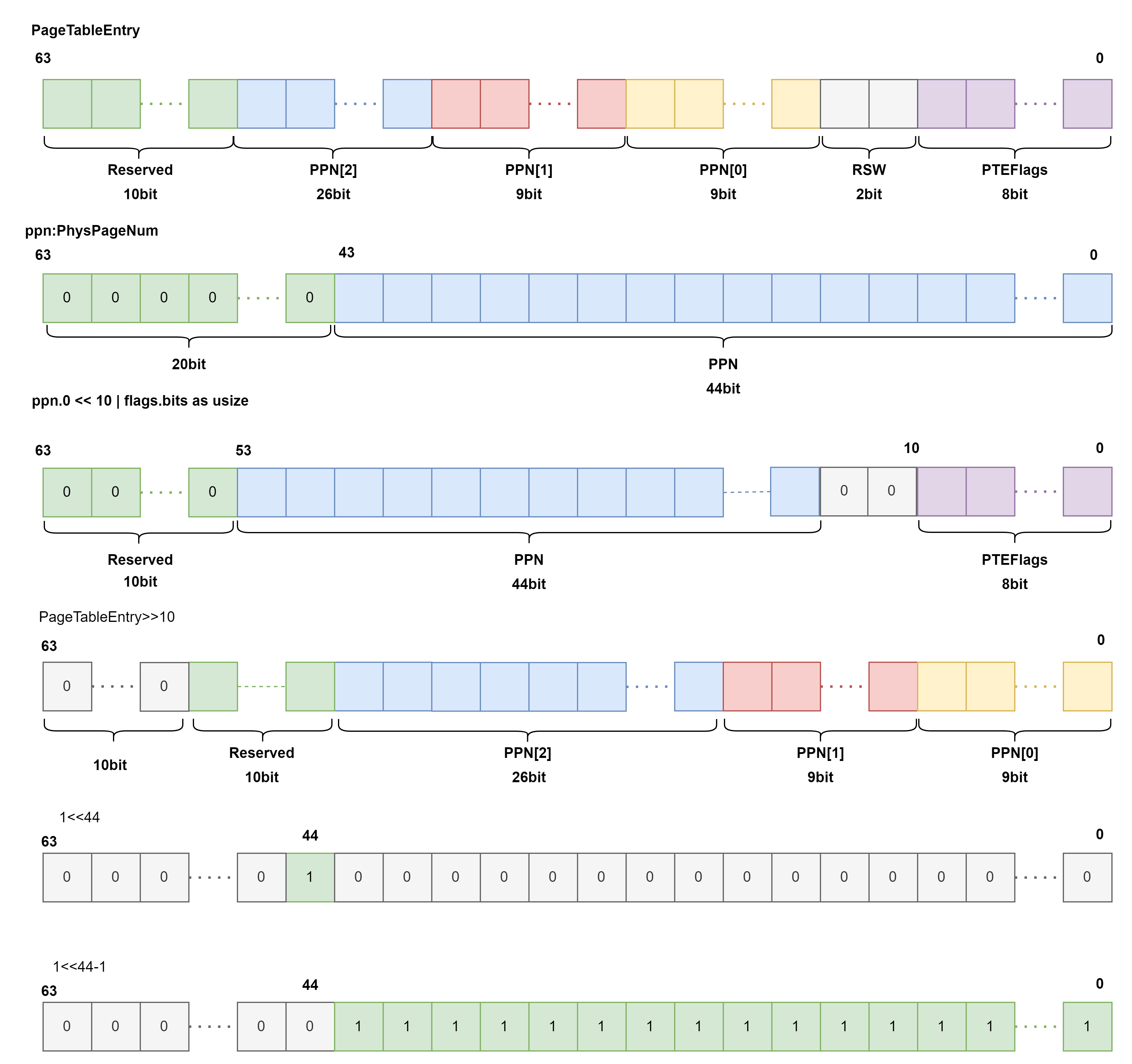
那么也可以继续实现一些有关于判断标志位的辅助函数:
// os/src/mm/page_table.rs
impl PageTableEntry {
pub fn is_valid(&self) -> bool {
(self.flags() & PTEFlags::V).bits() != PTEFlags::empty().bits()
}
}
这里注意新版本
bitflags的代码不允许PTEFlags直接进行比较了,于是我们通过比较它的bits().
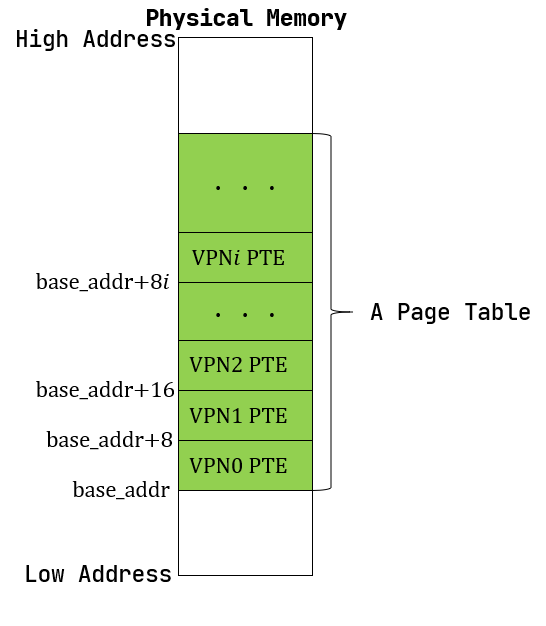
这个玩意还挺方便的,比如我们要访问VirtualPageNum是0的页表项,以映射到PhysicalPageNum的时候我们只需要计算base_addr+8i就可以访问到了.
这里比较难理解的就是后边它就直接开始计算了,好像所有的从第一个VirtualPageNum=0到最后一个VirtualPageNum=2^27都用掉了.
那当然了,假如说我们虽然中间的没用到的内存不去用,这里用一块那里用一块,是不是这一块内存都不能用了???这样就好理解了.
文档里的表达是:
由于虚拟页号有 \(2^{27}\) 种,每个虚拟页号对应一个 8 字节的页表项,则每个页表都需要消耗掉 1GiB 内存!
我们的理解是:由于虚拟页号有 \(2^{27}\) 种,每个虚拟页号对应一个 8 字节的页表项,则每个页表需要预留1GiB内存!
字典树的表述在参考手册,写的非常清楚了,我在这里就不重复了,一定要进去学会它.
TIPS:
这个字典树总是让我想到哈夫曼树,实际上是不一样的,哈弗曼树保存的是一行二进制代码对应的字符,字典树则是保存一串字符.
这里他讲完字典树就要直接让你把页表项迁移过去,这个实在是很难从他那几句话理解:
事实上 SV39 分页机制等价于一颗字典树。 27 位的虚拟页号可以看成一个长度 n=3 的字符串,字符集为 α={0,1,2,...,511} ,因为每一位字符都由 9 个比特组成。而我们也不再维护所谓字符串的计数,而是要找到字符串(虚拟页号)对应的页表项。因此,每个叶节点都需要保存 512 个 8 字节的页表项,一共正好 4KiB ,可以直接放在一个物理页帧内。而对于非叶节点来说,从功能上它只需要保存 512 个指向下级节点的指针即可,不过我们就像叶节点那样也保存 512 个页表项,这样每个节点都可以被放在一个物理页帧内,节点的位置可以用它所在物理页帧的物理页号来代替。当想从一个非叶节点向下走时,只需找到当前字符对应的页表项的物理页号字段,它就指向了下一级节点的位置,这样非叶节点中转的功能也就实现了。每个节点的内部是一个线性表,也就是将这个节点起始物理地址加上字符对应的偏移量就找到了指向下一级节点的页表项(对于非叶节点)或是能够直接用来地址转换的页表项(对于叶节点)。
我在这里画了一张图,我们通过这张图来理解,这里把虚拟内存进行分解,把前边27位的页表号给分成3个9位,那每一位能够表述的范围就是0~511一共512种.
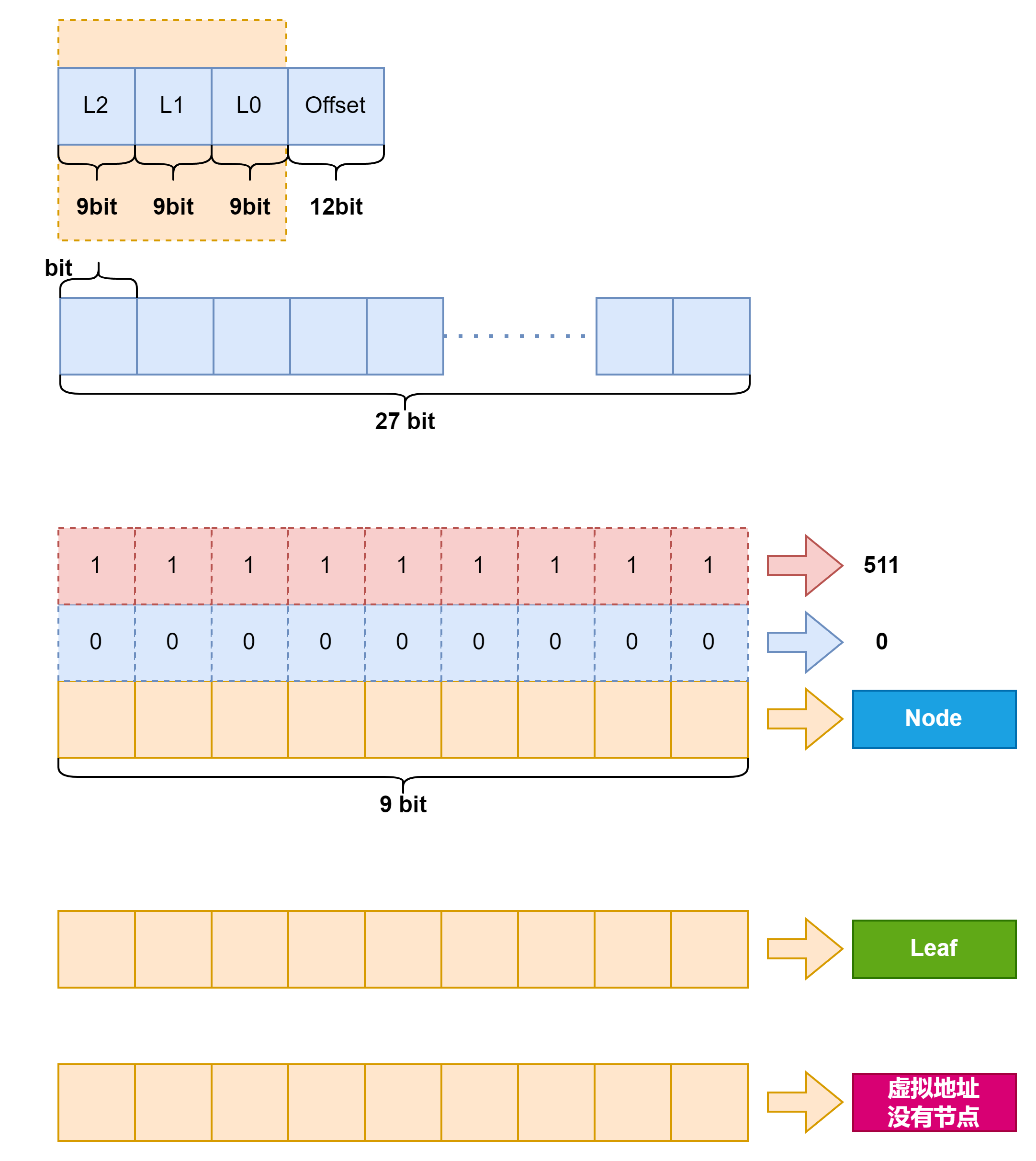
那么我们就可以把每一步的节点的前缀看成这个9bit的数,那么下一级又是9bit,因此Root节点(一级页表)下有512种变化,那么Node节点(二级页表)下也有512种变化,那么Leaf节点下对应的就是512种页表项.
这里是以0x000 0001为例的一个表示三级页表的字典树.
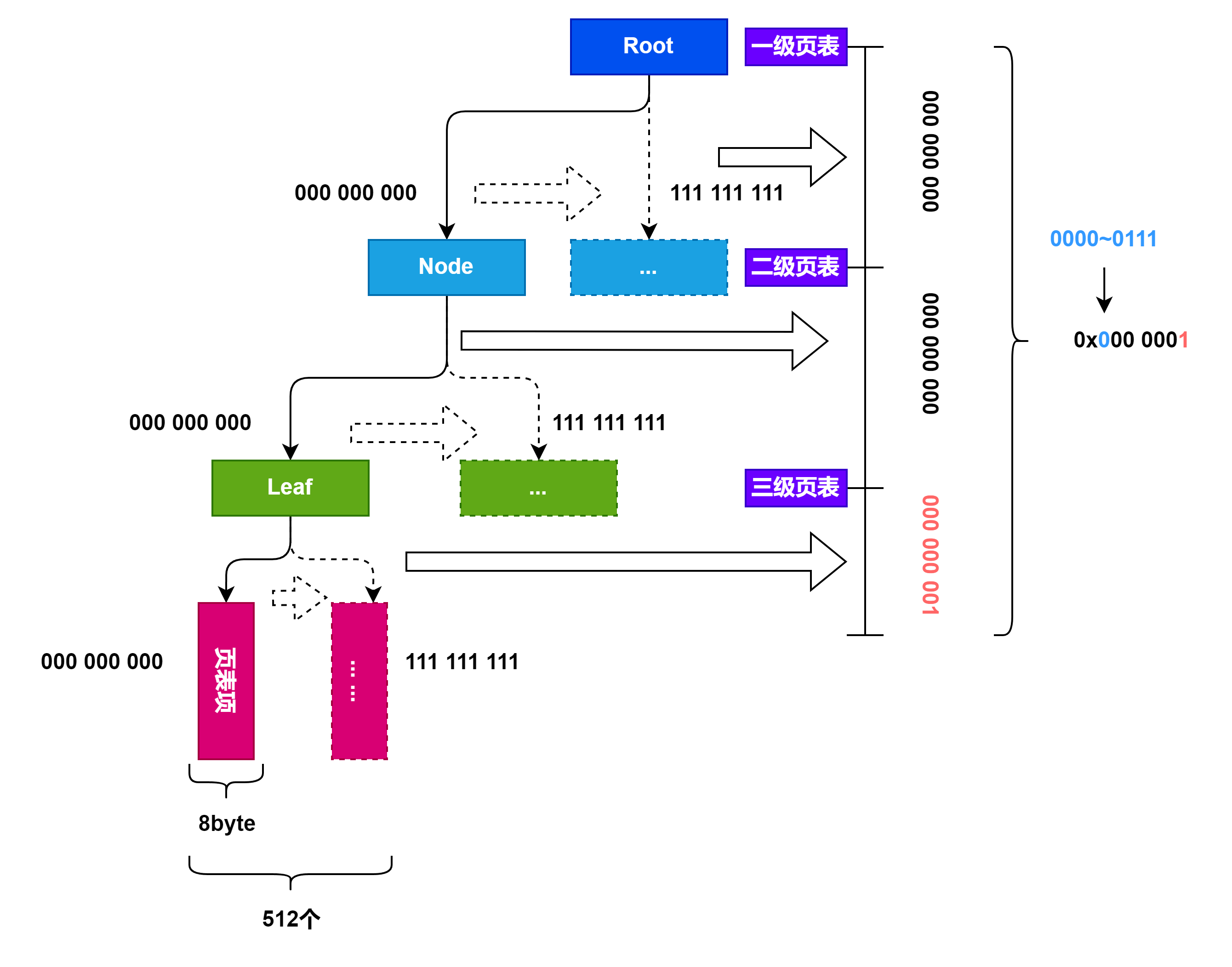
通过查页表项中的PNN自然可以访问到物理内存.

总结下来,查询的顺序是这样的:
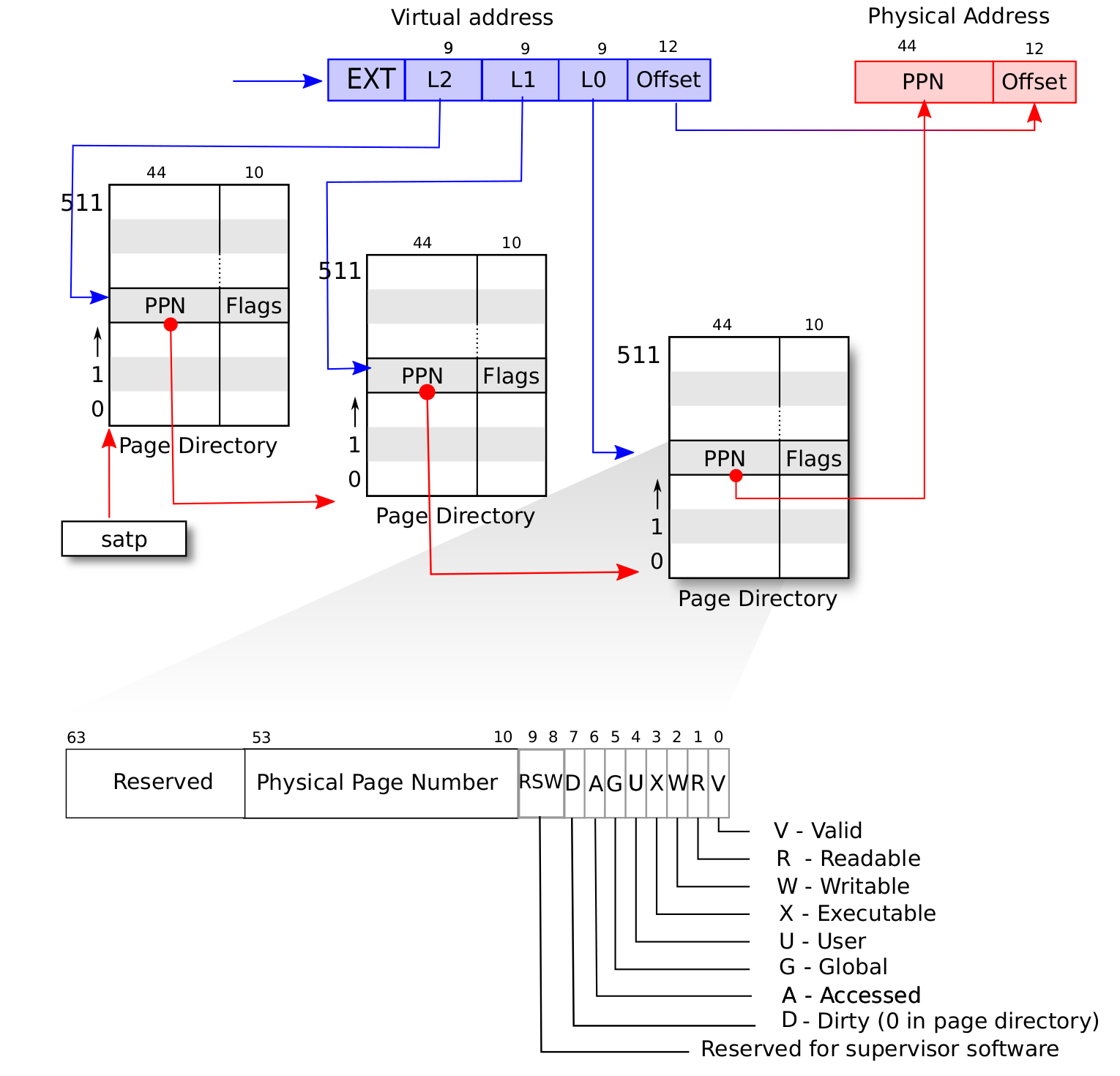
这里考虑到一个非常难想到的地方,就是页表项本身也存在物理内存里.
那么考虑叶子节点对应的页表项有512个,每个页表项有8byte,于是刚好占用了4KiB.
这里会想起我们当时设置的每个页面的大小为4KiB,那么每个节点刚好占据一个物理页面.
大页的是拓展部分,需要看SV39 多级页表的硬件机制 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档,这里不多纠结,因为这里和具体实现代码关系不大,我没有什么自己的理解.
这个部分也是直接看SV39 多级页表的硬件机制 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档.
这里比较难理解的部分就在于为什么突然他就开始除以2MiB,1GiB.
这个2MiB是这么计算的,三级页表每个节点下边有512个页表项,那么一个页表项是可以分配4KiB的内存的,512*4KiB=2MiB.他的意思是平均下来你每使用2MiB空间就需要创建一个三级节点.
同样地,平均分配1GiB空间就需要创建一个二级节点.
这里还有一个重点,就是页表项(节点)的消耗为8Byte,这和一个页表项能够分配的4KiB的内存是不同的,不要搞混了.
查页表的原理我们之前已经讲了,就是一级一级使用9bit的数据去查三级字典树.
对于 RISC-V的查页表过程还需要讲一下具体操作:
假设我们有虚拟地址
(VPN0,VPN1,VPN2,offset):
- 我们首先会记录装载「当前所用的一级页表的物理页」的页号到
satp寄存器中;- 把
VPN0作为偏移在一级页表的物理页中找到二级页表的物理页号;- 把
VPN1作为偏移在二级页表的物理页中找到三级页表的物理页号;- 把
VPN2作为偏移在三级页表的物理页中找到要访问位置的物理页号;- 物理页号对应的物理页基址(即物理页号左移12位)加上
offset就是虚拟地址对应的物理地址。
这里参考手册里的描述已经很好了,总结就是利用TLB的对映射进行缓存,这样就可以增加转换速度.
我们知道,物理内存的访问速度要比 CPU 的运行速度慢很多。如果我们按照页表机制循规蹈矩的一步步走,将一个虚拟地址转化为物理地址需要访问 3 次物理内存,得到物理地址后还需要再访问一次物理内存,才能完成访存。这无疑很大程度上降低了系统执行效率。
实践表明绝大部分应用程序的虚拟地址访问过程具有时间局部性和空间局部性的特点。因此,在 CPU 内部,我们使用MMU中的 快表(TLB, Translation Lookaside Buffer) 来作为虚拟页号到物理页号的映射的页表缓存。这部分知识在计算机组成原理课程中有所体现,当我们要进行一个地址转换时,会有很大可能对应的地址映射在近期已被完成过,所以我们可以先到 TLB 缓存里面去查一下,如果有的话我们就可以直接完成映射,而不用访问那么多次内存了。
上边进行描述的时候也讲求了:
satp那么不同的APP的页表不同,那么首先要改变一级页号,也就是要修改satp.
快表中的缓存也需要更新,因此需要使用sfence.vma指令来清空整个TLB.
 官方公众号
官方公众号