ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
Lookup Store 主要用于 Paimon 中的 Lookup Compaction 以及 Lookup join 的场景. 会将远程的列存文件在本地转化为 KV 查找的格式.
https://github.com/linkedin/PalDB
https://github.com/dain/leveldb
https://github.com/apache/paimon/pull/3770
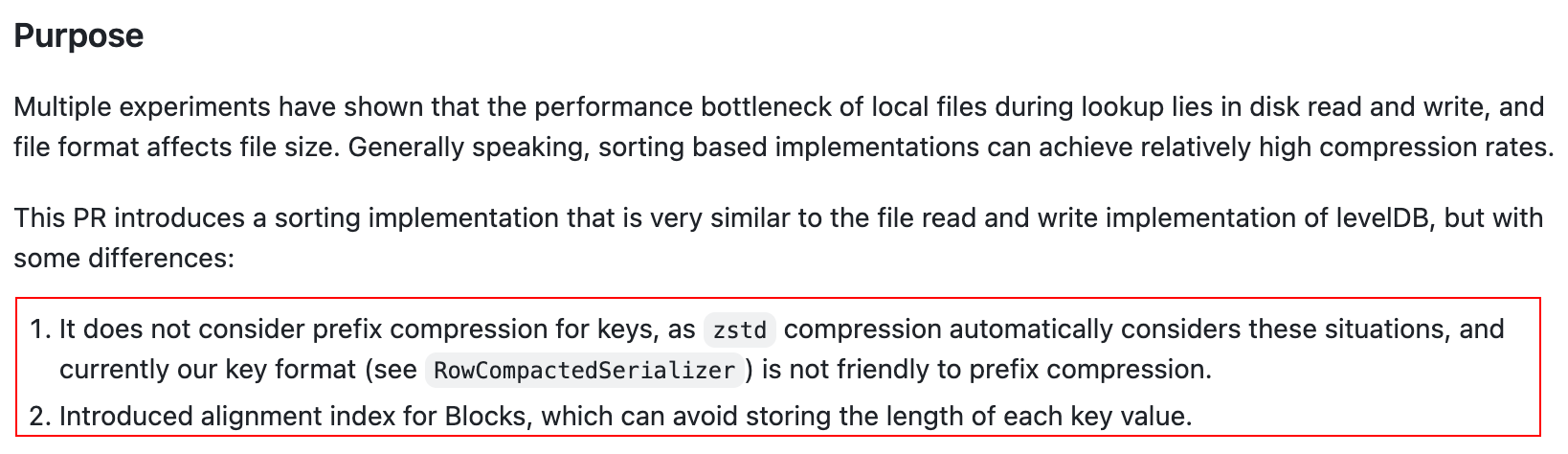
整体文件结构:
相比于 Hash file 的优势
SortLookupStoreWriter#put
@Override
public void put(byte[] key, byte[] value) throws IOException {
dataBlockWriter.add(key, value);
if (bloomFilter != null) {
bloomFilter.addHash(MurmurHashUtils.hashBytes(key));
}
lastKey = key;
// 当BlockWriter写入达到一定阈值, 默认是 cache-page-size=64kb.
if (dataBlockWriter.memory() > blockSize) {
flush();
}
recordCount++;
}
private void flush() throws IOException {
if (dataBlockWriter.size() == 0) {
return;
}
// 将data block写入数据文件, 并记录对应的position和长度
BlockHandle blockHandle = writeBlock(dataBlockWriter);
MemorySlice handleEncoding = writeBlockHandle(blockHandle);
// 将BlockHandle 写入index writer, 这也通过是一个BlockWriter写的
indexBlockWriter.add(lastKey, handleEncoding.copyBytes());
}
private BlockHandle writeBlock(BlockWriter blockWriter) throws IOException {
// close the block
// 获取block的完整数组, 此时blockWriter中的数组并不会被释放, 而是会继续复用
MemorySlice block = blockWriter.finish();
totalUncompressedSize += block.length();
// attempt to compress the block
BlockCompressionType blockCompressionType = BlockCompressionType.NONE;
if (blockCompressor != null) {
int maxCompressedSize = blockCompressor.getMaxCompressedSize(block.length());
byte[] compressed = allocateReuseBytes(maxCompressedSize + 5);
int offset = encodeInt(compressed, 0, block.length());
int compressedSize =
offset
+ blockCompressor.compress(
block.getHeapMemory(),
block.offset(),
block.length(),
compressed,
offset);
// Don't use the compressed data if compressed less than 12.5%,
if (compressedSize < block.length() - (block.length() / 8)) {
block = new MemorySlice(MemorySegment.wrap(compressed), 0, compressedSize);
blockCompressionType = this.compressionType;
}
}
totalCompressedSize += block.length();
// create block trailer
// 每一块block会有一个trailer, 记录压缩类型和crc32校验码
BlockTrailer blockTrailer =
new BlockTrailer(blockCompressionType, crc32c(block, blockCompressionType));
MemorySlice trailer = BlockTrailer.writeBlockTrailer(blockTrailer);
// create a handle to this block
// BlockHandle 记录了每个block的其实position和长度
BlockHandle blockHandle = new BlockHandle(position, block.length());
// write data
// 将数据追加写入磁盘文件
writeSlice(block);
// write trailer: 5 bytes
// 写出trailer
writeSlice(trailer);
// clean up state
blockWriter.reset();
return blockHandle;
}
public LookupStoreFactory.Context close() throws IOException {
// flush current data block
flush();
LOG.info("Number of record: {}", recordCount);
// write bloom filter
@Nullable BloomFilterHandle bloomFilterHandle = null;
if (bloomFilter != null) {
MemorySegment buffer = bloomFilter.getBuffer();
bloomFilterHandle =
new BloomFilterHandle(position, buffer.size(), bloomFilter.expectedEntries());
writeSlice(MemorySlice.wrap(buffer));
LOG.info("Bloom filter size: {} bytes", bloomFilter.getBuffer().size());
}
// write index block
// 将index数据写出至文件
BlockHandle indexBlockHandle = writeBlock(indexBlockWriter);
// write footer
// Footer 记录bloomfiler + index
Footer footer = new Footer(bloomFilterHandle, indexBlockHandle);
MemorySlice footerEncoding = Footer.writeFooter(footer);
writeSlice(footerEncoding);
// 最后关闭文件
// close file
fileOutputStream.close();
LOG.info("totalUncompressedSize: {}", MemorySize.ofBytes(totalUncompressedSize));
LOG.info("totalCompressedSize: {}", MemorySize.ofBytes(totalCompressedSize));
return new SortContext(position);
}
public void add(byte[] key, byte[] value) {
int startPosition = block.size();
// 写入key长度
block.writeVarLenInt(key.length);
// 写入key
block.writeBytes(key);
// 写入value长度
block.writeVarLenInt(value.length);
// 写入value
block.writeBytes(value);
int endPosition = block.size();
// 使用一个int数组记录每个KV pair的起始位置作为索引
positions.add(startPosition);
// 是否对齐. 是否对齐取决于每个KV对的长度是否一样
if (aligned) {
int currentSize = endPosition - startPosition;
if (alignedSize == 0) {
alignedSize = currentSize;
} else {
aligned = alignedSize == currentSize;
}
}
}
byte[] , 当写入长度超过当前数组的长度时, 就会扩容public MemorySlice finish() throws IOException {
if (positions.isEmpty()) {
throw new IllegalStateException();
}
// 当通过BlockWriter写出的数据长度都是对齐的时, 就不需要记录各个Position的index了, 只需要记录一个对齐长度, 读取时自己可以计算.
if (aligned) {
block.writeInt(alignedSize);
} else {
for (int i = 0; i < positions.size(); i++) {
block.writeInt(positions.get(i));
}
block.writeInt(positions.size());
}
block.writeByte(aligned ? ALIGNED.toByte() : UNALIGNED.toByte());
return block.toSlice();
}
整个文件的写出过程非常简单, 就是按 block 写出, 并且记录每个 block 的位置, 作为 index.
读取的过程, 主要就是为了查找 key 是否存在, 以及对应的 value 或者对应的行号.
public byte[] lookup(byte[] key) throws IOException {
// 先通过bloomfilter提前进行判断
if (bloomFilter != null && !bloomFilter.testHash(MurmurHashUtils.hashBytes(key))) {
return null;
}
MemorySlice keySlice = MemorySlice.wrap(key);
// seek the index to the block containing the key
indexBlockIterator.seekTo(keySlice);
// if indexIterator does not have a next, it means the key does not exist in this iterator
if (indexBlockIterator.hasNext()) {
// seek the current iterator to the key
// 根据从index block中读取到的key value的位置(BlockHandle), 读取对应的value block
BlockIterator current = getNextBlock();
// 在value的iterator中再次二分查找寻找对应block中是否存在match的key, 如果存在则返回对应的数据
if (current.seekTo(keySlice)) {
return current.next().getValue().copyBytes();
}
}
return null;
}
// 从block创建一个iterator
public BlockIterator iterator() {
BlockAlignedType alignedType =
BlockAlignedType.fromByte(block.readByte(block.length() - 1));
int intValue = block.readInt(block.length() - 5);
if (alignedType == ALIGNED) {
return new AlignedIterator(block.slice(0, block.length() - 5), intValue, comparator);
} else {
int indexLength = intValue * 4;
int indexOffset = block.length() - 5 - indexLength;
MemorySlice data = block.slice(0, indexOffset);
MemorySlice index = block.slice(indexOffset, indexLength);
return new UnalignedIterator(data, index, comparator);
}
}
这里面传入了 keyComparator, 用于进行 key 的比较. 用于在 index 中进行二分查找. 这里的比较并不是直接基于原始的数据, 而是基于 MemorySlice 进行排序.
比较的过程会将 key 的各个字段从 MemorySegment 中读取反序列化出来, cast 成 Comparable 进行比较.
public SliceComparator(RowType rowType) {
int bitSetInBytes = calculateBitSetInBytes(rowType.getFieldCount());
this.reader1 = new RowReader(bitSetInBytes);
this.reader2 = new RowReader(bitSetInBytes);
this.fieldReaders = new FieldReader[rowType.getFieldCount()];
for (int i = 0; i < rowType.getFieldCount(); i++) {
fieldReaders[i] = createFieldReader(rowType.getTypeAt(i));
}
}
@Override
public int compare(MemorySlice slice1, MemorySlice slice2) {
reader1.pointTo(slice1.segment(), slice1.offset());
reader2.pointTo(slice2.segment(), slice2.offset());
for (int i = 0; i < fieldReaders.length; i++) {
boolean isNull1 = reader1.isNullAt(i);
boolean isNull2 = reader2.isNullAt(i);
if (!isNull1 || !isNull2) {
if (isNull1) {
return -1;
} else if (isNull2) {
return 1;
} else {
FieldReader fieldReader = fieldReaders[i];
Object o1 = fieldReader.readField(reader1, i);
Object o2 = fieldReader.readField(reader2, i);
@SuppressWarnings({"unchecked", "rawtypes"})
int comp = ((Comparable) o1).compareTo(o2);
if (comp != 0) {
return comp;
}
}
}
}
return 0;
}
查找的实现就是二分查找的过程, 因为写入的 key 是有序写入的.
public boolean seekTo(MemorySlice targetKey) {
int left = 0;
int right = recordCount - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
// 对于aligned iterator, 就直接seek record * recordSize
// 对于unaligned iterator, 就根据writer写入的索引表来跳转
seekTo(mid);
// 读取一条key value pair
BlockEntry midEntry = readEntry();
int compare = comparator.compare(midEntry.getKey(), targetKey);
if (compare == 0) {
polled = midEntry;
return true;
} else if (compare > 0) {
polled = midEntry;
right = mid - 1;
} else {
left = mid + 1;
}
}
return false;
}
查找过程
 官方公众号
官方公众号