ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
在介绍DataLoader之前,需要先了解数据集DataSet的使用。Pytorch中集成了很多已经处理好的数据集,在pytorch的torchvision、torchtext等模块有一些典型的数据集,可以通过配置来下载使用。
以CIFAR10 数据集为例,文档已经描述的很清晰了,其中要注意的就是transform这个参数,可以用来将图像转换为所需要的格式,就比如这样,将PIL格式的图像转化为tensor格式的图像:
# 准备的测试数据集
test_data=torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
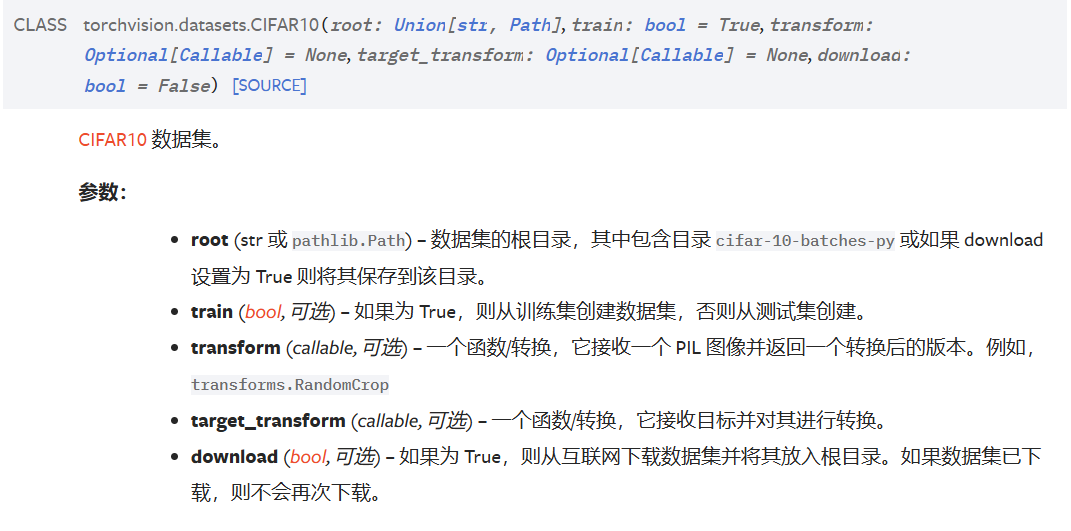
我们可以这样理解:如果Dataset数据集是一个存储所有数据(图像、音频)的容器,那么DataLoader就是另一个具有更好收纳功能的容器,其中分隔开来很多小隔间,可以自己设定一个小隔间有多少个数据集的数据来组成,每次将数据放进收纳小隔间的时候要不要把源数据集打乱再进行收纳等等
也就是说,给定了一个数据集,我们可以决定如何从数据集里面拿取数据来进行训练,比如一次拿取多少数据作为一个对象来对数据集进行分割,对数据集进行分割之前要不要打乱数据集等等。DataLoader的结果就是一个对数据集进行分割的大字典列表,列表中的每个对象都是由设置的多少个数据集的对象组合而成的
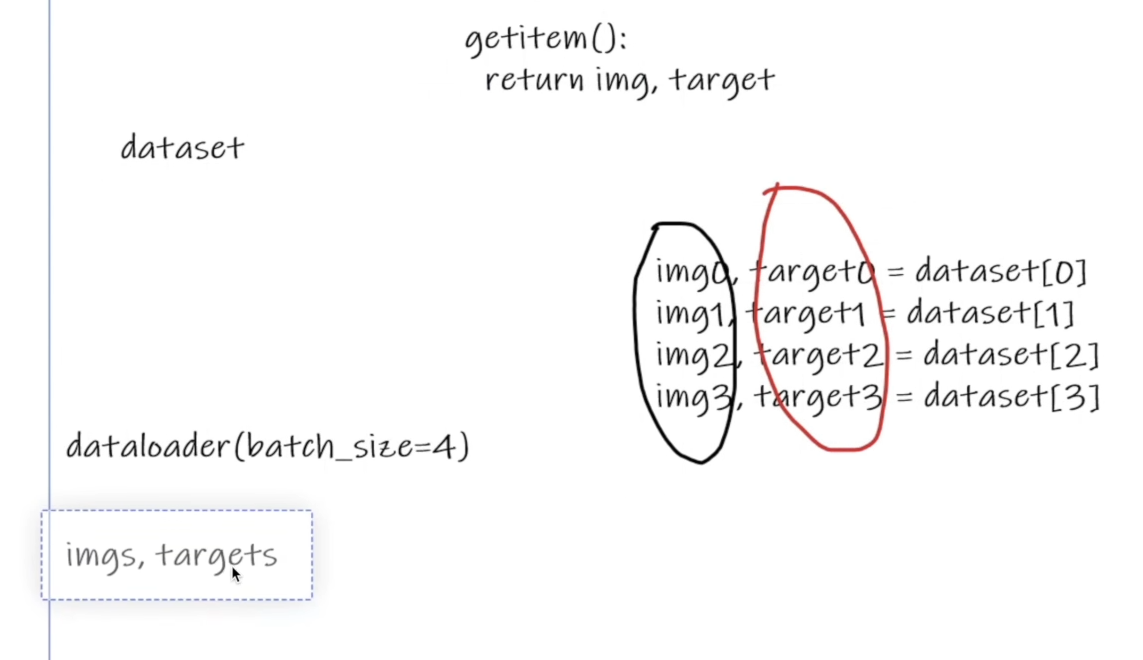
首先需要先理解__getitem__方法,__getitem__被称为魔法方法,在python中定义一个类的时候,如果想要通过键来得到类的输出值,就需要__getitem__方法。所以__getitem__方法的作用就是在调用类的时候自动的运行__getitem__方法的内容,得结果并返回
class Fib(): #定义类Fib
def __init__(self,start=0,step=1):
self.step=step
def __getitem__(self, key): #定性__getitem__函数,key为类Fib的键
a = key+self.step
return a #当按照键取值时,返回的值为a
s=Fib()
s[1] #返回2 ,因为类有 __getitem__方法,所以可以直接通过键来取对应的值
如果没有__getitem__方法,那么就无法通过键来得到返回值
class Fib(): #定义类Fib
def __init__(self,start=0,step=1):
self.step=step
s=Fib()
s[1]
返回:TypeError: 'Fib' object does not support indexing
以Pytorch中的CIFAR10数据集为例,可以看到源码中的__getitem__方法是这样的:
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], self.targets[index]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
可以理解为在调用类的时候如果输入index,也就是这个类中的索引/键,那么就可以自动调用__getitem__方法得到返回值image和target,其中image就是数据集中的图像,target是标签类class中的索引,用来指示label是什么
可以在Pytorch的Documents文档中查看DataLoader的使用方法,一部分截图如下所示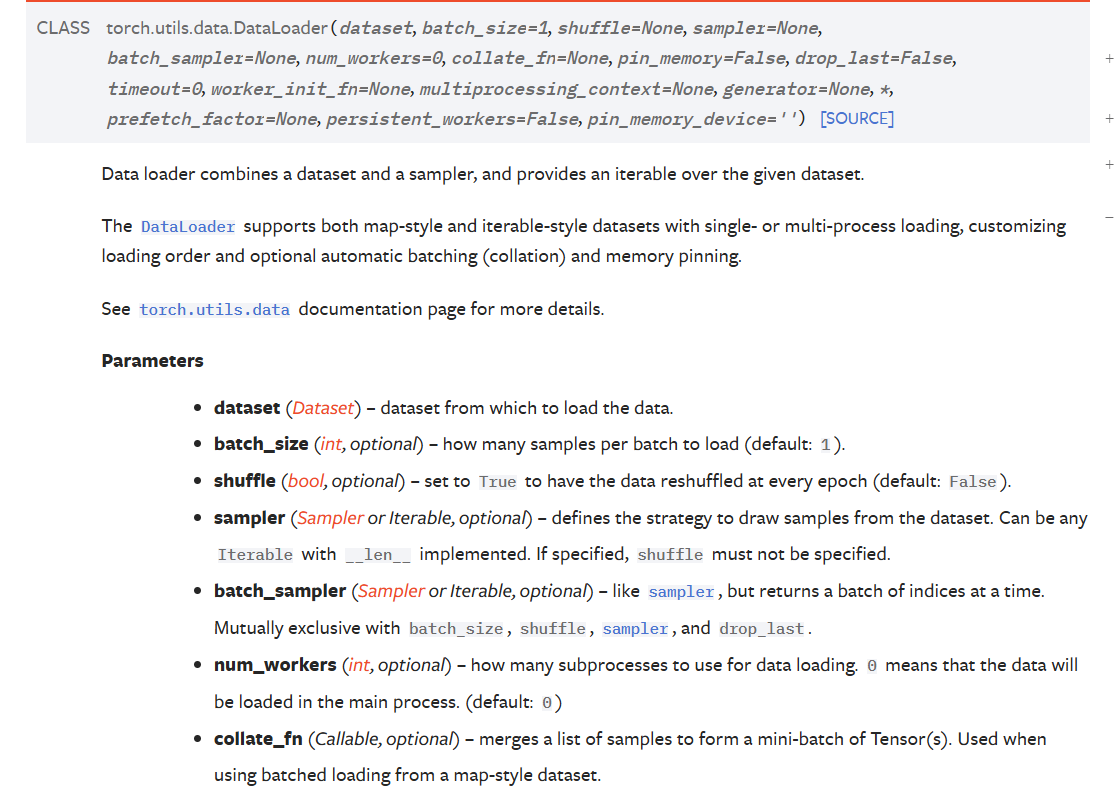
这里介绍几个比较常用的:
dataset:就是我们的数据集,我们构建好数据集对象之后传入即可
batch_size:也就是在数据集容器中一次拿取多少数据,然后这一次拿取的数据就作为一个Dataloader中的一个对象。如果还是不太理解,可以看下面的示例:
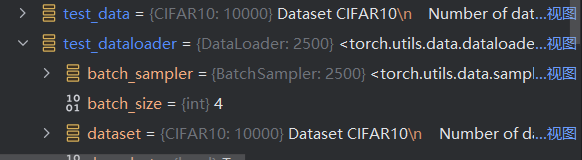
第一张图片是我设置batch_size=4的时候给出的DataLoader中的一个对象,第二张图片是batch_size=64的时候给出的DataLoader中的一个对象,这样就好理解了~


在这里也可以很清楚的看出来,数据集是10000张图像/对象,设置batch_size=4之后DataLoader中就是2500个对象了
shuffle:是否在每次操作的时候打乱数据集,一般选择为True。更好的理解就是,如果设置为true,那么第一次创建DataLoader对象中的每个小对象和第二次DataLoader对象中的小对象是不相同的,因为在每次创建DataLoader的时候就会先把数据集打乱,自然得到的DataLoader也就不一样
num_workers:多线程进行拿取数据操作,0表示只在主线程中操作,一般来讲windows系统下用多线程会报错,设置为0即可
drop_last:如果拿取数据有余数,是否保留最后剩下的部分。如果为True的话,最后剩下的部分被丢弃,为false的话最后剩下的部分不会被丢弃
例如在后面的代码中,如果我设置drop_last=False,那么一共有156次数据拿取,并且最后一次剩余的部分不会被丢弃
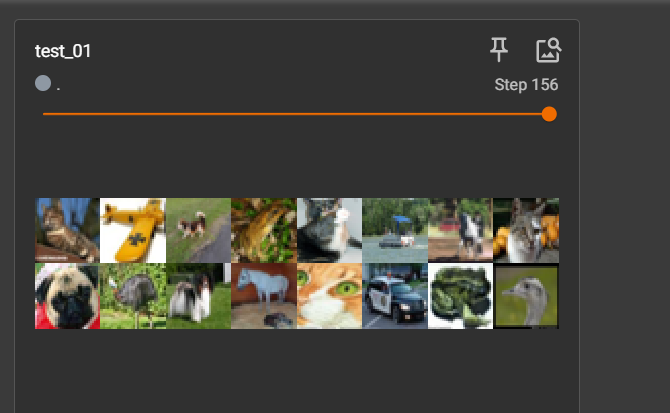
如果设置drop_last=True,那么最后剩余的部分被丢弃,并且拿取次数也少了一次

初步使用的代码如下:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data=torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载Dataloader
test_dataloader=DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=True)
# 加载tensorboard
writer=SummaryWriter("logs")
# tensorboard中的图片序号
step=0
for data in test_dataloader:
images,targets=data
writer.add_images("test_03",images,step)
step=step+1
writer.close()
然后配合使用tensorboard就可以直观体会到它的使用方法了~
 官方公众号
官方公众号