ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
ByteTrack是字节跳动与2021年10月份公开的一个全新的多目标跟踪算法,原论文是《ByteTrack: Multi-Object Tracking by Associating Every Detection Box》。
ByteTrak的MOTA和FPS等指标上都实现了较好的性能,要优于现有的大多数MOT(多目标追踪)算法。
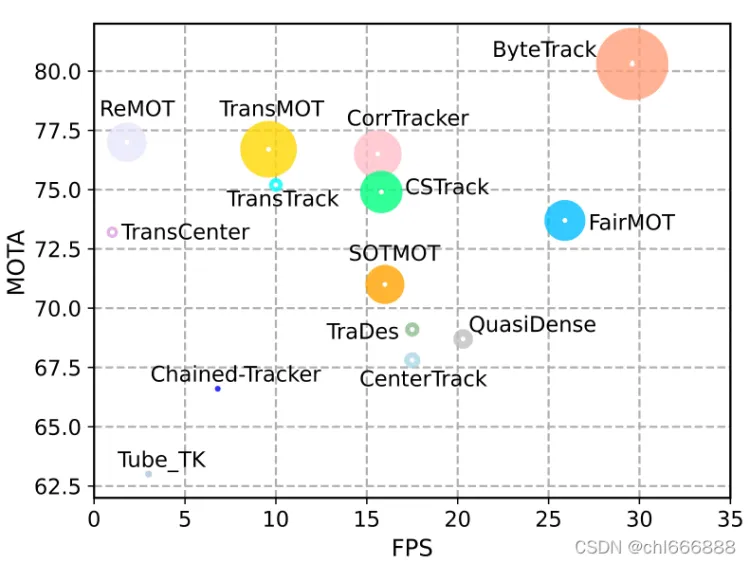
github地址:https://github.com/ifzhang/ByteTrack
演示:
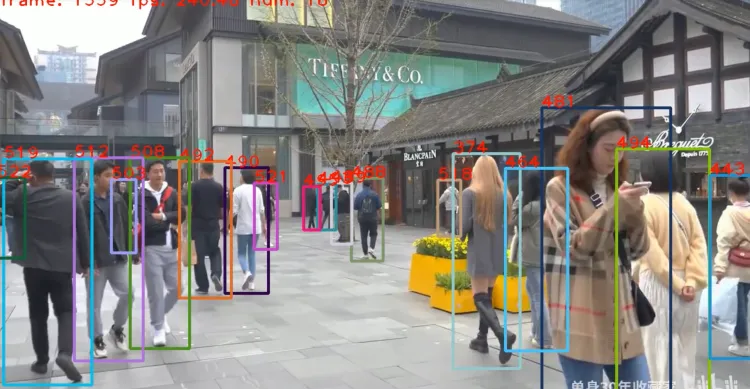
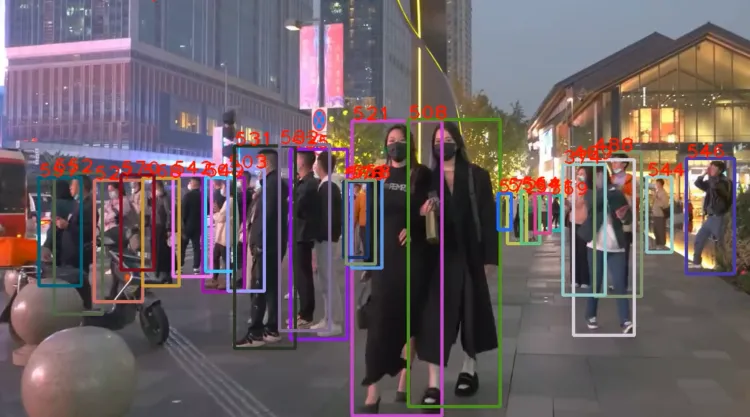
先前的多目标追踪算法一般在完成当前帧的目标检测后只会保留置信度比较大的检测框用于进行目标跟踪,比如图中置信度为0.9和0.8的目标框。
而在ByteTrack中,作者保留了所有的检测框并且通过阈值将它们分成了高置信度检测框和低置信度检测框。ByteTrack 可以有效解决一些遮挡,且能够保持较低的 ID Switch。因为目标会因为被遮挡检测置信度有所降低,当重新出现时,置信度会有所升高。算法特点在于:
ByteTrack 并不是连接所有检测框形成一个追踪轨迹,而是通过预测和验证的方法来确定追踪轨迹。对于每一个轨迹使用卡尔曼滤波来预测轨迹下一个位置(预测框),然后计算检测框和预测框的IOU,最后通过匈牙利算法匹配IOU,返回匹配成功和失败的轨迹。
追踪算法的详细步骤:
在介绍代码之前首先要了解基础概念。ByteTrack 主要由两个类组成,一个是轨迹管理类STrack,一个轨迹匹配逻辑处理类BYTETracker。
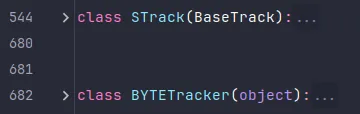
Strack 是轨迹的类,每一个实例都是一个轨迹。Strack拥有核心方法包括:
# 这个类是用来存放轨迹的,每个轨迹都有一些自己的属性,例如id、边界框、预测框、状态等等
class STrack(BaseTrack):
# 单例模式
shared_kalman = KalmanFilter()
def __init__(self, tlwh, score):
self._tlwh = np.asarray(tlwh, dtype=np.float)
self.kalman_filter = None
# 保存卡尔曼滤波对这个轨迹的平均值和协方差
self.mean, self.covariance = None, None
# 是否是激活状态
self.is_activated = False
# 轨迹分数
self.score = score
# 轨迹追踪的帧数,每次追踪成功都会+1
self.tracklet_len = 0
def predict(self):
mean_state = self.mean.copy()
if self.state != TrackState.Tracked:
mean_state[7] = 0
self.mean, self.covariance = self.kalman_filter.predict(mean_state, self.covariance)
@staticmethod
def multi_predict(stracks):
if len(stracks) > 0:
multi_mean = np.asarray([st.mean.copy() for st in stracks])
multi_covariance = np.asarray([st.covariance for st in stracks])
for i, st in enumerate(stracks):
if st.state != TrackState.Tracked:
multi_mean[i][7] = 0
multi_mean, multi_covariance = STrack.shared_kalman.multi_predict(multi_mean, multi_covariance)
for i, (mean, cov) in enumerate(zip(multi_mean, multi_covariance)):
stracks[i].mean = mean
stracks[i].covariance = cov
def activate(self, kalman_filter, frame_id):
"""Start a new tracklet"""
self.kalman_filter = kalman_filter
self.track_id = self.next_id()
self.mean, self.covariance = self.kalman_filter.initiate(self.tlwh_to_xyah(self._tlwh))
self.tracklet_len = 0
self.state = TrackState.Tracked
if frame_id == 1:
self.is_activated = True
# self.is_activated = True
self.frame_id = frame_id
self.start_frame = frame_id
def re_activate(self, new_track, frame_id, new_id=False):
self.mean, self.covariance = self.kalman_filter.update(
self.mean, self.covariance, self.tlwh_to_xyah(new_track.tlwh)
)
self.tracklet_len = 0
self.state = TrackState.Tracked
self.is_activated = True
self.frame_id = frame_id
if new_id:
self.track_id = self.next_id()
self.score = new_track.score
def update(self, new_track, frame_id):
"""
Update a matched track
:type new_track: STrack
:type frame_id: int
:type update_feature: bool
:return:
"""
self.frame_id = frame_id
self.tracklet_len += 1
new_tlwh = new_track.tlwh
self.mean, self.covariance = self.kalman_filter.update(
self.mean, self.covariance, self.tlwh_to_xyah(new_tlwh))
self.state = TrackState.Tracked
self.is_activated = True
self.score = new_track.score
@property
# @jit(nopython=True)
def tlwh(self):
"""Get current position in bounding box format `(top left x, top left y,
width, height)`.
"""
if self.mean is None:
return self._tlwh.copy()
ret = self.mean[:4].copy()
ret[2] *= ret[3]
ret[:2] -= ret[2:] / 2
return ret
@property
# @jit(nopython=True)
def tlbr(self):
"""Convert bounding box to format `(min x, min y, max x, max y)`, i.e.,
`(top left, bottom right)`.
"""
ret = self.tlwh.copy()
ret[2:] += ret[:2]
return ret
@staticmethod
# @jit(nopython=True)
def tlwh_to_xyah(tlwh):
"""Convert bounding box to format `(center x, center y, aspect ratio,
height)`, where the aspect ratio is `width / height`.
"""
ret = np.asarray(tlwh).copy()
ret[:2] += ret[2:] / 2
ret[2] /= ret[3]
return ret
def to_xyah(self):
return self.tlwh_to_xyah(self.tlwh)
@staticmethod
# @jit(nopython=True)
def tlbr_to_tlwh(tlbr):
ret = np.asarray(tlbr).copy()
ret[2:] -= ret[:2]
return ret
@staticmethod
# @jit(nopython=True)
def tlwh_to_tlbr(tlwh):
ret = np.asarray(tlwh).copy()
ret[2:] += ret[:2]
return ret
def __repr__(self):
return 'OT_{}_({}-{})'.format(self.track_id, self.start_frame, self.end_frame)
BYTETracker 是轨迹创建、更新、删除等流程类。拥有一个主要的方法,那就是update。通过预测框和已存在轨迹的运算不断更新轨迹路线。代码实现的流程图如下:
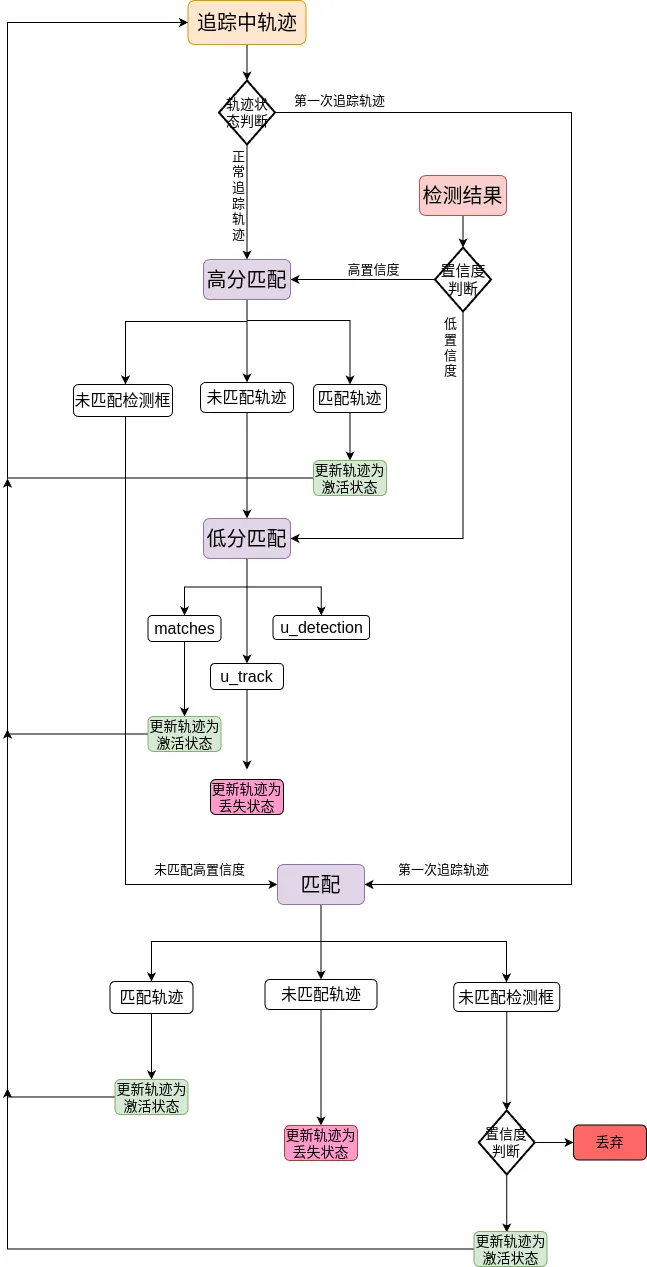
下面分析代码实现流程
初始化参数,包括需要保存的追踪轨迹、丢失轨迹、删除轨迹、高低分阈值等。追踪的工作原理是对每一帧进行判断处理,同时也需要对连续帧判断,所以这里定义的就是全局保存的轨迹。
class BYTETracker(object):
def __init__(self, args, frame_rate=30):
# 已追踪的轨迹
self.tracked_stracks = [] # type: list[STrack]
# 丢失的轨迹
self.lost_stracks = [] # type: list[STrack]
# 删除的轨迹
self.removed_stracks = [] # type: list[STrack]
self.frame_id = 0
self.args = args
#self.det_thresh = args.track_thresh
# 区分高低分检测框的阈值
self.det_thresh = args.track_thresh + 0.1
# 最大丢失时间
self.buffer_size = int(frame_rate / 30.0 * args.track_buffer)
self.max_time_lost = self.buffer_size
# 卡尔曼滤波器
self.kalman_filter = KalmanFilter()
定义每一帧流程处理之后的结果,包括追踪到的轨迹、重新追踪到的轨迹、丢失的轨迹等
def update(self, output_results):
self.frame_id += 1
# 以下列表是本轮匹配中临时结果存放的列表
# 保存当前帧标记为追踪到轨迹
activated_starcks = []
# 保存当前帧标记为追踪到之前丢失的轨迹
refind_stracks = []
# 保存当前帧标记为丢失的目标轨迹
lost_stracks = []
# 保存当前帧标记为丢失的轨迹
removed_stracks = []
筛选出高分框和低分框
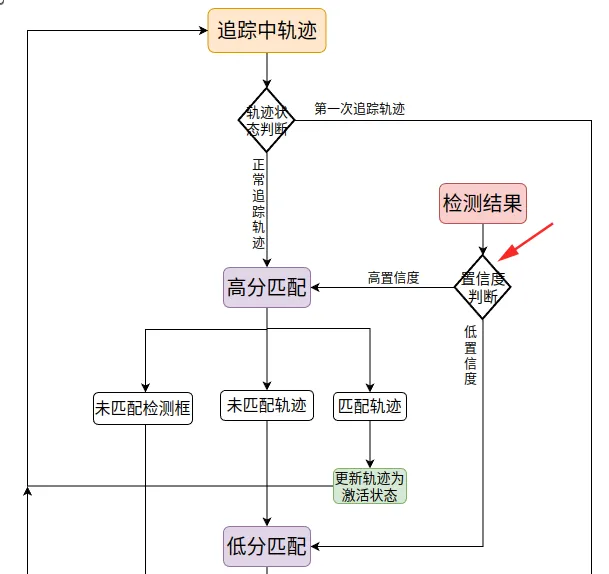
# 高分框
remain_inds = scores > self.args.track_thresh
# 低分框0.1-阈值之间
inds_low = scores > 0.1
inds_high = scores < self.args.track_thresh
# 筛选分数处于0.1<分数<阈值
inds_second = np.logical_and(inds_low, inds_high)
dets_second = bboxes[inds_second]
scores_second = scores[inds_second]
# 筛选分数超过阈值
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]
筛选出正常追踪轨迹和第一次追踪轨迹
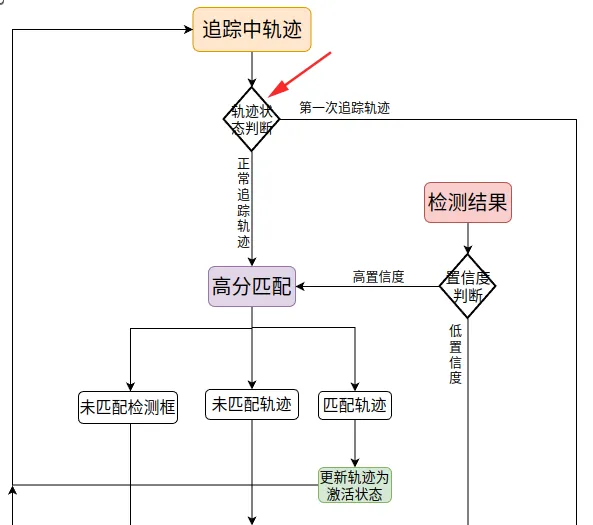
# 处于追踪阶段但是未激活的,也就是只追上了一帧的目标。也就是第一次追踪的轨迹
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
高分匹配,并根据三种匹配结果分别做不同的处理
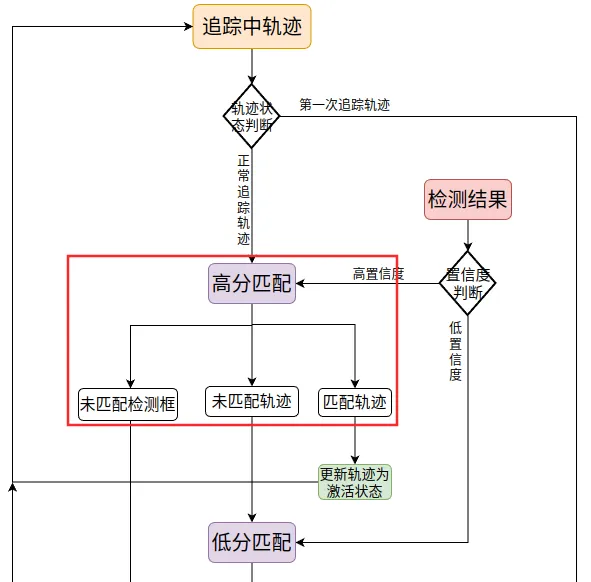
"""------------第一次匹配,高分检测框匹配-----------"""
# 将追踪状态为激活和标记为丢失的轨迹合并得到track_pool
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)
# 将strack_pool送入muti_predict进行预测(卡尔曼滤波)
STrack.multi_predict(strack_pool)
# 计算strack_pool中轨迹的预测框和detections检测框的iou_distance(代价矩阵)
dists = matching.iou_distance(strack_pool, detections)
if not self.args.mot20:
dists = matching.fuse_score(dists, detections)
# 用匹配阈值match_thresh=0.8过滤较小的iou,利用匈牙利算法进行匹配,得到匹配成功的轨迹, 未匹配成功的轨迹, 未匹配成功的检测框
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=self.args.match_thresh)
# 遍历matches,轨迹之前状态为Tracked,调用update方法,并加入到activated_stracks。
# 轨迹之前的状态不是Tracked的,调用re_activate,并加入refind_stracks
# matches = [itracked, idet] itracked是轨迹的索引,idet是当前检测框的索引,意思是第几个轨迹匹配第几个目标框
for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
# 更新轨迹预测框为当前检测框
track.update(detections[idet], self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
# refind_stracks是重新追踪到的轨迹
refind_stracks.append(track)
低分匹配,并做不同的处理。
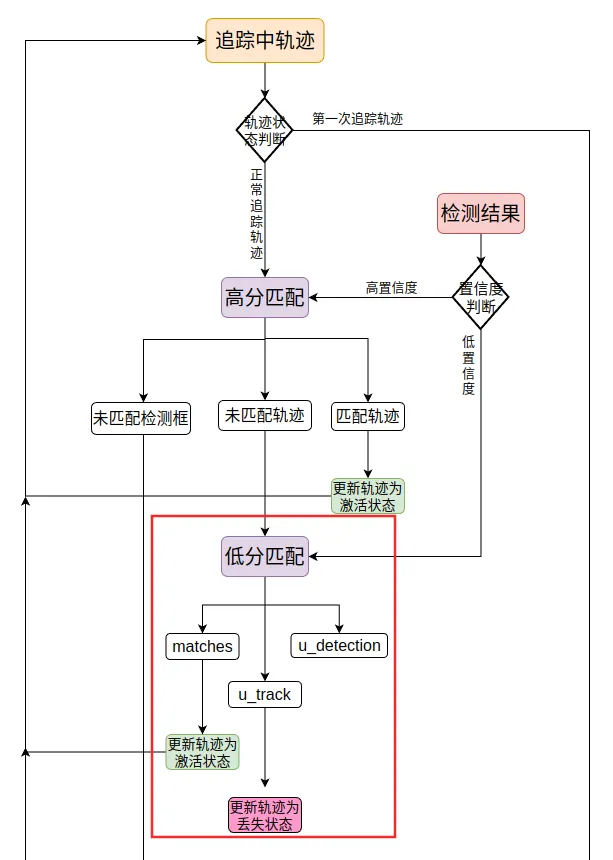
"""-------------第二次匹配:低分检测框匹配-----------------"""
if len(dets_second) > 0:
detections_second = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets_second, scores_second)]
else:
detections_second = []
# 找出第一次匹配后没匹配到的轨迹
r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]
# 第一次未匹配的轨迹和低置信度检测框的匹配
dists = matching.iou_distance(r_tracked_stracks, detections_second)
# 用匹配阈值match_thresh = 0.5 过滤较小的iou,利用匈牙利算法进行匹配,得到matches, u_track, u_detection
matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)
# 遍历matches,轨迹之前状态为Tracked,调用update方法,并加入到activated_stracks。
# 轨迹之前的状态不是Tracked的,调用re_activate,并加入refind_stracks
for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
# 遍历u_track(第二次匹配也没匹配到的轨迹),将state不是Lost的轨迹,调用mark_losk方法,并加入lost_stracks,等待下一帧匹配(本流程开始时会合并追踪状态轨迹和丢失状态轨迹)。
# 一个轨迹既没有被高分检测框匹配,也没有被低分检测框匹配,那么就会被当作丢失轨迹
for it in u_track:
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost:
track.mark_lost()
# lost_stracks:上一帧还在持续追踪但是这一帧两次匹配不到的轨迹
lost_stracks.append(track)
第三次匹配,将未匹配的高分框和第一次追踪的轨迹匹配。
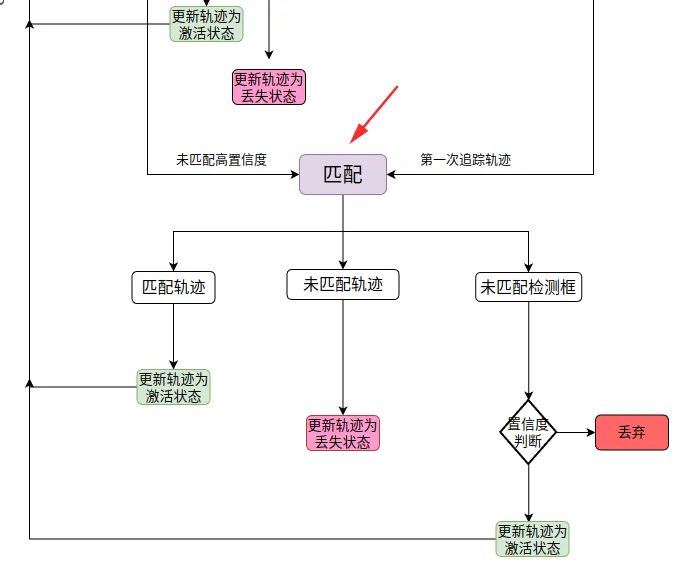
"""----------第三次匹配,处理之前没有匹配上的高分检测框-------------"""
# 没有匹配上的高分检测框
detections = [detections[i] for i in u_detection]
# unconfirmed是第一次出现的目标,生成了轨迹但是不是激活状态。计算第一次出现的目标和没有匹配上的高分检测框的iou_distance
dists = matching.iou_distance(unconfirmed, detections)
if not self.args.mot20:
dists = matching.fuse_score(dists, detections)
# 用阈值match_thresh=0.8过滤较小的iou,利用匈牙利算法进行匹配,得到matches, u_track, u_detection
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.8)
# 遍历匹配的轨迹,更新状态为激活,并将轨迹保存到当前活跃轨迹中
for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])
# 遍历未匹配轨迹,调用mark_removd方法,并加入removed_stracks
for it in u_unconfirmed:
# 中途出现一次的轨迹和当前目标框匹配失败,删除该轨迹,认为是检测器误判
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
最后将未匹配上的高分检测框再次判断,符合条件就设置成新轨迹
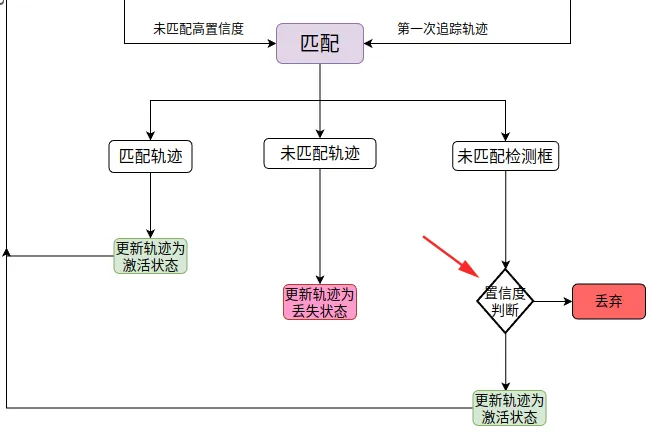
# 遍历未匹配上的高分检测框,对于score大于self.det_thresh,调用activate方法,并加入activated_stracks
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
# 新建轨迹并调用activate。新建轨迹的激活状态:如果视频开始第一帧就新建轨迹那么激活状态为True,剩下帧新建轨迹激活状态都是False
track.activate(self.kalman_filter, self.frame_id)
#把新的轨迹加入到当前活跃轨迹中
activated_starcks.append(track)
最后就是将每一帧匹配的结果更新到全局结果中,然后进行一轮匹配。
可以匹配的流程图上看出来,ByteTrack 不仅对高分框感兴趣,而且对低分框有关注。将低分框当作疑似遮挡的目标,将高分框当作匹配的轨迹或者新轨迹,这样有效追踪遮挡的物体,提高追踪的准确性。
完整代码:
class BYTETracker(object):
def __init__(self, args, frame_rate=30):
# 已追踪的轨迹
self.tracked_stracks = [] # type: list[STrack]
# 丢失的轨迹
self.lost_stracks = [] # type: list[STrack]
# 删除的轨迹
self.removed_stracks = [] # type: list[STrack]
self.frame_id = 0
self.args = args
#self.det_thresh = args.track_thresh
# 区分高低分检测框的阈值
self.det_thresh = args.track_thresh + 0.1
# 最大丢失时间
self.buffer_size = int(frame_rate / 30.0 * args.track_buffer)
self.max_time_lost = self.buffer_size
# 卡尔曼滤波器
self.kalman_filter = KalmanFilter()
def update(self, output_results):
self.frame_id += 1
# 以下列表是本轮匹配中临时结果存放的列表
# 保存当前帧标记为追踪到轨迹
activated_starcks = []
# 保存当前帧标记为追踪到之前丢失的轨迹
refind_stracks = []
# 保存当前帧标记为丢失的目标轨迹
lost_stracks = []
# 保存当前帧标记为丢失的轨迹
removed_stracks = []
# 第一步:将objects转换为x1,y1,x2,y2,score的格式,并构建strack
if output_results.shape[1] == 5:
scores = output_results[:, 4]
bboxes = output_results[:, :4]
else:
output_results = output_results.cpu().numpy()
scores = output_results[:, 4] * output_results[:, 5]
bboxes = output_results[:, :4] # x1y1x2y2
# 根据传入的阈值将检测框分为高分框和低分框
# 高分框
remain_inds = scores > self.args.track_thresh
# 低分框0.1-阈值之间
inds_low = scores > 0.1
inds_high = scores < self.args.track_thresh
# 筛选分数处于0.1<分数<阈值
inds_second = np.logical_and(inds_low, inds_high)
dets_second = bboxes[inds_second]
scores_second = scores[inds_second]
# 筛选分数超过阈值
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]
# 初始化追踪轨迹
if len(dets) > 0:
'''Detections'''
detections = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for (tlbr, s) in zip(dets, scores_keep)]
else:
detections = []
''' Add newly detected tracklets to tracked_stracks'''
# 遍历保存state为Tracked的数组self.tracked_stracks,每一个元素代表一个轨迹,每个轨迹的state为Tracked,但是有激活状态的区分
# is_activated: 追踪状态为激活的轨迹,也就是至少追上了两帧以上的轨迹
# 处于追踪阶段但是未激活的,也就是只追上了一帧的目标。也就是第一次追踪的轨迹
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
"""------------第一次匹配,高分检测框匹配-----------"""
# 将追踪状态为激活和标记为丢失的轨迹合并得到track_pool
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)
# 将strack_pool送入muti_predict进行预测(卡尔曼滤波)
STrack.multi_predict(strack_pool)
# 计算strack_pool中轨迹的预测框和detections检测框的iou_distance(代价矩阵)
dists = matching.iou_distance(strack_pool, detections)
if not self.args.mot20:
dists = matching.fuse_score(dists, detections)
# 用匹配阈值match_thresh=0.8过滤较小的iou,利用匈牙利算法进行匹配,得到匹配成功的轨迹, 未匹配成功的轨迹, 未匹配成功的检测框
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=self.args.match_thresh)
# 遍历matches,轨迹之前状态为Tracked,调用update方法,并加入到activated_stracks。
# 轨迹之前的状态不是Tracked的,调用re_activate,并加入refind_stracks
# matches = [itracked, idet] itracked是轨迹的索引,idet是当前检测框的索引,意思是第几个轨迹匹配第几个目标框
for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
# 更新轨迹预测框为当前检测框
track.update(detections[idet], self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
# refind_stracks是重新追踪到的轨迹
refind_stracks.append(track)
"""-------------第二次匹配:低分检测框匹配-----------------"""
if len(dets_second) > 0:
detections_second = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets_second, scores_second)]
else:
detections_second = []
# 找出第一次匹配后没匹配到的轨迹
r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]
# 第一次未匹配的轨迹和低置信度检测框的匹配
dists = matching.iou_distance(r_tracked_stracks, detections_second)
# 用匹配阈值match_thresh = 0.5 过滤较小的iou,利用匈牙利算法进行匹配,得到matches, u_track, u_detection
matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)
# 遍历matches,轨迹之前状态为Tracked,调用update方法,并加入到activated_stracks。
# 轨迹之前的状态不是Tracked的,调用re_activate,并加入refind_stracks
for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
# 遍历u_track(第二次匹配也没匹配到的轨迹),将state不是Lost的轨迹,调用mark_losk方法,并加入lost_stracks,等待下一帧匹配(本流程开始时会合并追踪状态轨迹和丢失状态轨迹)。
# 一个轨迹既没有被高分检测框匹配,也没有被低分检测框匹配,那么就会被当作丢失轨迹
for it in u_track:
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost:
track.mark_lost()
# lost_stracks:上一帧还在持续追踪但是这一帧两次匹配不到的轨迹
lost_stracks.append(track)
"""----------第三次匹配,处理之前没有匹配上的高分检测框-------------"""
# 没有匹配上的高分检测框
detections = [detections[i] for i in u_detection]
# unconfirmed是第一次出现的目标,生成了轨迹但是不是激活状态。计算第一次出现的目标和没有匹配上的高分检测框的iou_distance
dists = matching.iou_distance(unconfirmed, detections)
if not self.args.mot20:
dists = matching.fuse_score(dists, detections)
# 用阈值match_thresh=0.8过滤较小的iou,利用匈牙利算法进行匹配,得到matches, u_track, u_detection
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.8)
# 遍历匹配的轨迹,更新状态为激活,并将轨迹保存到当前活跃轨迹中
for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])
# 遍历未匹配轨迹,调用mark_removd方法,并加入removed_stracks
for it in u_unconfirmed:
# 中途出现一次的轨迹和当前目标框匹配失败,删除该轨迹,认为是检测器误判
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
# 遍历未匹配上的高分检测框,对于score大于self.det_thresh,调用activate方法,并加入activated_stracks
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
# 新建轨迹并调用activate。新建轨迹的激活状态:如果视频开始第一帧就新建轨迹那么激活状态为True,剩下帧新建轨迹激活状态都是False
track.activate(self.kalman_filter, self.frame_id)
#把新的轨迹加入到当前活跃轨迹中
activated_starcks.append(track)
# 遍历lost_stracks,对于丢失超过max_time_lost(30)的轨迹,调用mark_removed方法,并加入removed_stracks
for track in self.lost_stracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
# 收集所有状态为Tracked的轨迹,包括本轮更新的activated_starcks和refind_stracks,以及上一轮的self.tracked_stracks
# 遍历tracked_stracks,筛选出state为Tracked的轨迹,保存到tracked_stracks。self.tracked_stracks中在本轮匹配中如果两轮都没有匹配上会被置为lost状态
self.tracked_stracks = [t for t in self.tracked_stracks if t.state == TrackState.Tracked]
# 将activated_stracks,refind_stracks合并到track_stracks
self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_starcks)
self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)
# 更新self.lost_stracks保存的轨迹,从self.lost_stracks中剔除变成追踪状态的轨迹
self.lost_stracks = sub_stracks(self.lost_stracks, self.tracked_stracks)
self.lost_stracks.extend(lost_stracks)
# 更新self.removed_stracks保存的轨迹, 从self.removed_stracks中剔除变成追踪状态的轨迹
self.lost_stracks = sub_stracks(self.lost_stracks, self.removed_stracks)
self.removed_stracks.extend(removed_stracks)
# 调用remove_duplicate_stracks函数,计算tracked_stracks,lost_stracks的iou_distance,对于iou_distance<0.15的认为是同一个轨迹,
# 对比该轨迹在track_stracks和lost_stracks的跟踪帧数和长短,仅保留长的那个
self.tracked_stracks, self.lost_stracks = remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)
# 遍历self.tracked_stracks,将所有的is_activated为true的轨迹输出
output_stracks = [track for track in self.tracked_stracks if track.is_activated]
return output_stracks
def joint_stracks(tlista, tlistb):
exists = {}
res = []
for t in tlista:
exists[t.track_id] = 1
res.append(t)
for t in tlistb:
tid = t.track_id
if not exists.get(tid, 0):
exists[tid] = 1
res.append(t)
return res
def sub_stracks(tlista, tlistb):
stracks = {}
for t in tlista:
stracks[t.track_id] = t
for t in tlistb:
tid = t.track_id
if stracks.get(tid, 0):
del stracks[tid]
return list(stracks.values())
def remove_duplicate_stracks(stracksa, stracksb):
pdist = matching.iou_distance(stracksa, stracksb)
pairs = np.where(pdist < 0.15)
dupa, dupb = list(), list()
for p, q in zip(*pairs):
timep = stracksa[p].frame_id - stracksa[p].start_frame
timeq = stracksb[q].frame_id - stracksb[q].start_frame
if timep > timeq:
dupb.append(q)
else:
dupa.append(p)
resa = [t for i, t in enumerate(stracksa) if not i in dupa]
resb = [t for i, t in enumerate(stracksb) if not i in dupb]
return resa, resb
参考:
https://blog.csdn.net/wentinghappyday/article/details/128376299
https://blog.csdn.net/weixin_43731103/article/details/123665507
csdn付费文档,惠存
目标跟踪之 MOT 经典算法:ByteTrack 算法原理以及多类别跟踪-CSDN博客.pdf
多目标跟踪(MOT)中的卡尔曼滤波(Kalman filter)和匈牙利(Hungarian)算法详解_mot 卡尔曼滤波-CSDN博客.pdf
 官方公众号
官方公众号