ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录

1. 什么是全文检索
1.1 数据的分类
结构化数据
特点:数据的类型固定,格式固定,长度固定...
例如:数据库中存放的数据都是结构化的数据
非结构化数据
特点:数据的类型不固定,格式不固定,长度不固定...
例如:word文档,PDF文档,邮件,html网页文件,txt文本文件...
1.2 数据的查询
结构化数据的查询
SQL语句,查询结构化数据的语言,其特点是简单 速度快
非结构化数据的查询
例如 一个文本文件中的内容有很多 此时我们应该怎么查询?
a. 目测 - 顺序扫描
b. 使用程序将文件内容读取到内存中 然后匹配字符串 - 顺序扫描
c. 把非结构化的数据变成结构化的数据
先根据空格对文件中的内容进行拆分,这样就能得到一个单词列表,然后在基于这个单词列表创建一个索引
然后在查询索引,最后根据单词和文档的对应关系找到文档列表,这个过程就是全文检索
* 索引:索引是为了提高查询速度,创建的某种数据结构的结合
1.3 全文检索的概念:
先创建索引 然后查询索引的过程就是全文检索
索引是一次创建可以多次重复使用的,使用索引 每次查询速度很快
2. 全文检索的应用场景
只要是有搜索的地方就可以使用全文检索技术
2.1 搜索引擎
如 google,百度...
2.2 站内搜素
如 论坛,博客,微博等
2.3 电商搜索
如 淘宝,京东等
3. 什么是Lucene
Lucene是一个基于Java语言开发的全文检索工具包,是apache的一个子项目,是免费开源的
Elasticsearch,Solar等 其底层实现均为Lucene实现
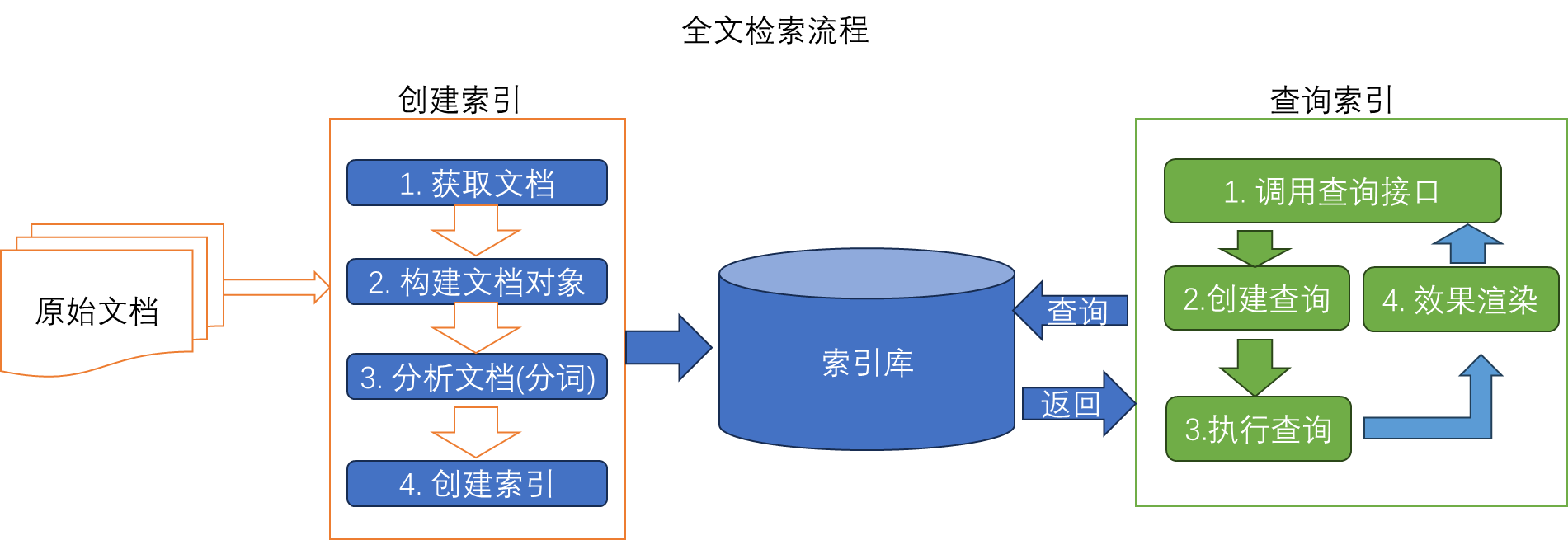
全文检索流程
全文检索如下图所示
1 创建索引
1.1 获得文档:
原始文档:
原始文档是我们需要基于哪些数据来进行搜索 那么这些数据就是原始数据 也叫做原始文档
搜索引擎:
使用爬虫技术获得原始文档
站内搜索:
使用数据库中的数据作为原始文档
磁盘文件:
直接使用IO流读取本地磁盘上的文件作为原始文档
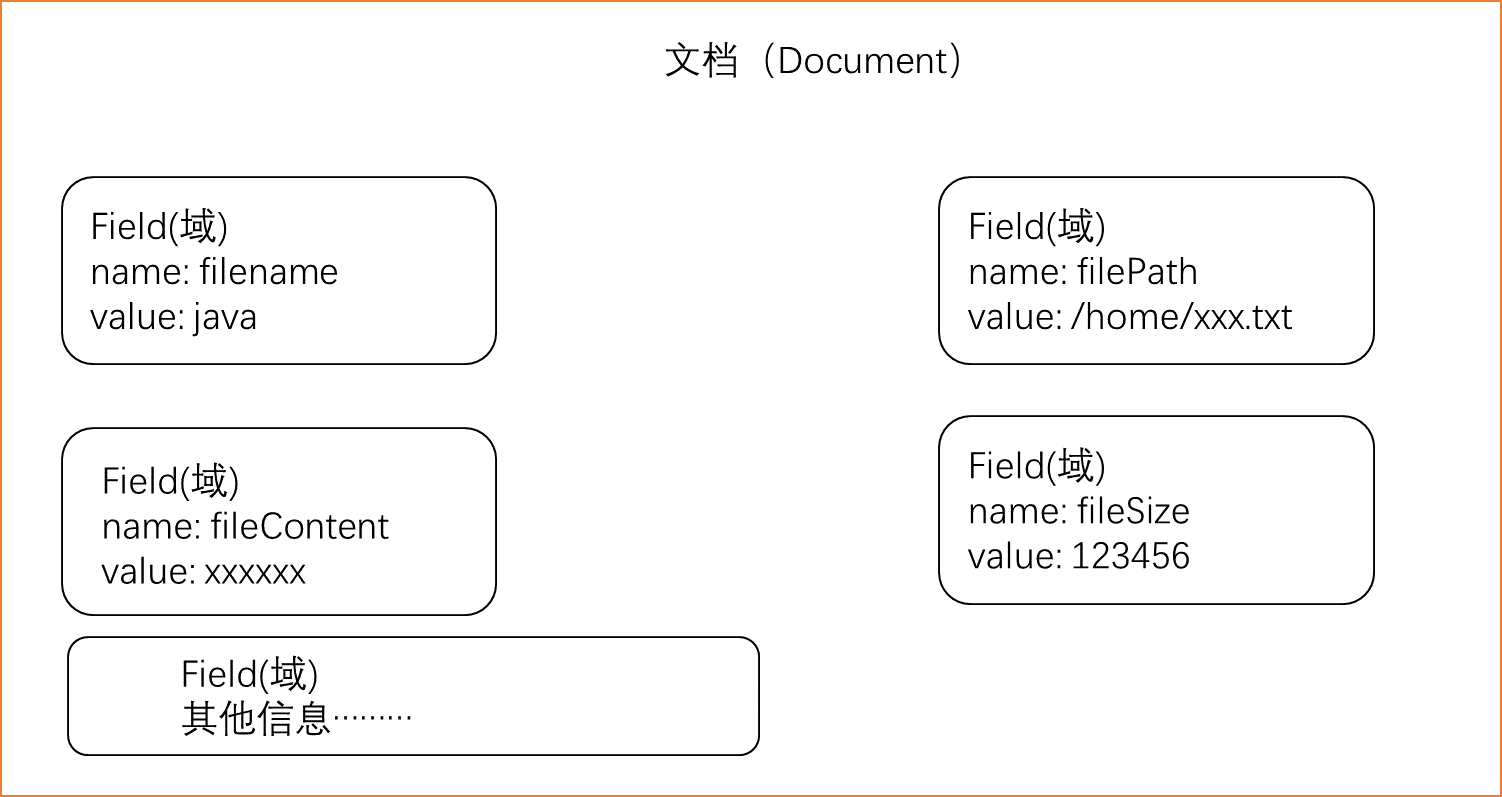
1.2 构建文档对象
对应每个原始文档创建一个Document对象,一个文档相当于数据库中的一条数据
每个文档对象中包含多个域(Field) 也就是多个字段
域中保存的就是原始文档的数据
每个域包含两部分 域的名称(相当于key) 域的值(相当于value)
* 每个文档对象都有一个唯一的编号,就是文档的ID
1.3 分析文档
分析文档就是分词的过程
例如 文本文件中存放的英文短文
a. 根据空格进行字符串拆分,得到一个单词列表
b. 将列表中的单词统一转成大写或小写
c. 去除标点符号
d. 去除停用词
停用词就是不单独表示含义的词 如 and , a,the 等
e. 每个关键词都封装到一个Term对象中
一个Term就是一个关键词
Term对象包含两部分内容
关键词所在的域(Field)
关键词本身
注意:不同的域中拆分出来的相同的关键词是不同的Term
例如 文件名保存一个域中,文件内容保存一个域中
文件名中包含的关键词和文件内容中相同的关键词 是两个不同的Term
1.4 创建索引
基于关键词列表创建一个索引并保存到索引库中(索引库就是磁盘上的文件)
2 索引库
索引库中包含三部分
索引、document对象、关键词和文档对象的对应关系
倒排索引
索引的目的就是为了提高查询速度,在查询时有一个倒排索引的概念
正排序
例如 我们要查询一个关键字 首先找到文档 在从文档中找到对应的关键字
倒排序
倒排索引指的是通过关键词找到文档 这种索引结构就是倒排索引
3 查询索引
3.1 用户查询接口
用户输入查询条件的地方
如:搜索框
3.2 将输入的关键词封装成一个对象
该对象包含两部分
要查询的域和要查询的关键词
3.3 执行查询
根据要查询的关键词到对应的域上进行查询
先找到关键词 在根据关键词找到对应的文档
3.4 渲染结果
根据文档ID找到文档对象
对关键词高亮显示
对数据分页处理
最终展示到页面
 官方公众号
官方公众号
