ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
数据资产管理是一项系统而复杂的工程,涉及到元数据、数据血缘、数据质量、数据服务、数据监控、数据安全、数据权限等众多方面,为了更高效的管理好数据资产,因此在很多大型的企业或者组织中,通常会构建一个数据资产管理平台来管理这些各种各样的数据资产,数据资产管理平台通常会包含如下功能: 关注清哥聊技术公众号,获取更多权威技术文章。
1、数据资产的架构设计
数据资产架构是指为了让数据资产管理更加信息化、高效化、平台化而构建的一套系统架构。通常来说数据资产架构会包含如下的一些方面:
1.1、数据获取层
数据获取层通常又叫数据采集层,主要负责从各种不同的数据源中去获取数据,如下图
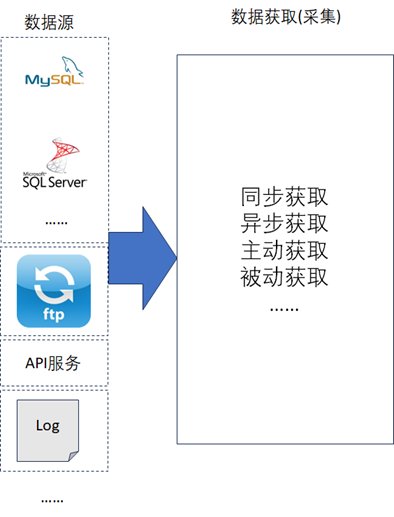
数据获取层在获取数据时会存在多种不同类型的数据源,从每一种类型的数据源中获取数据的方式是不一样的,所以在数据获取层的架构设计中,需要考虑兼容多种不同数据源,并且在出现新的类型的数据源时,需要能够支持花最小的代码改造代价去做扩展。所以通常建议数据资产架构设计中数据获取层的架构可以设计成即插即用的插件类型,如下图所示,这种设计方式可以很好的解决数据源的可扩展性的问题。
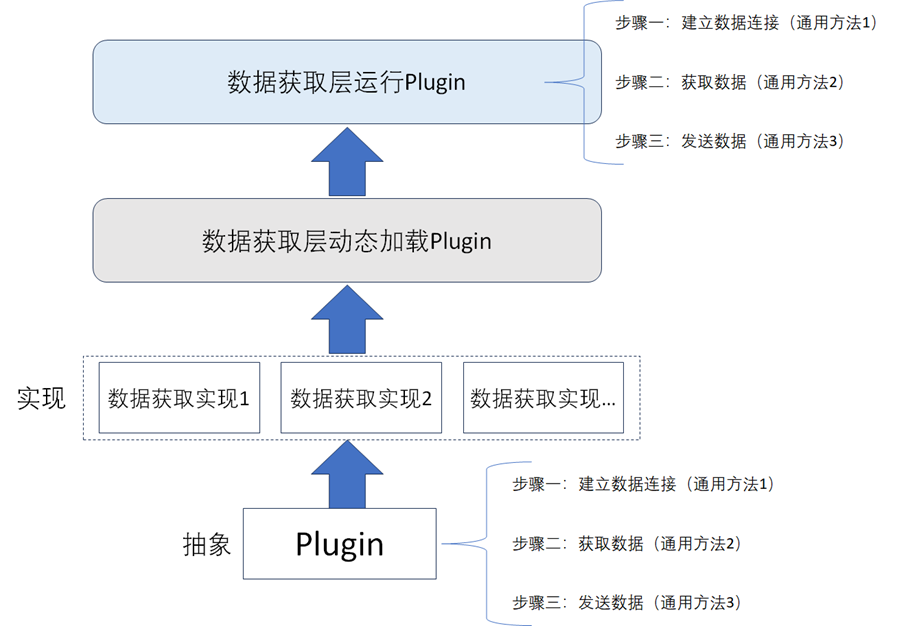
从图中可以看到
1.2、数据处理层
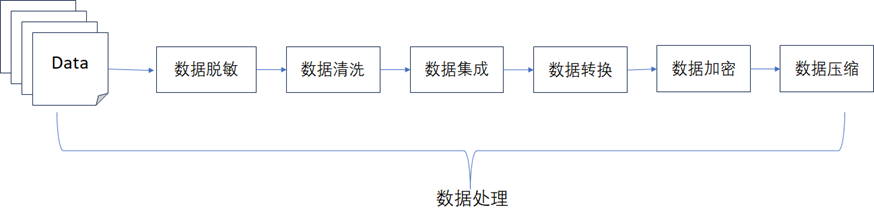
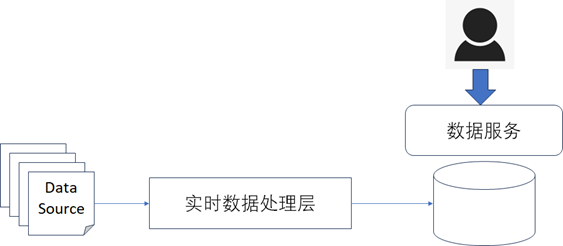
数据处理层主要负责将从不同数据源中获取到的数据做处理,是整个数据资产架构的核心部分,数据处理的方式通常包含实时和离线两种方式,通常情况下数据处理层需要完成的主要功能如下图所示。
在大数据处理中,最常用的架构方式就是Lambda架构和Kappa架构,如下所示
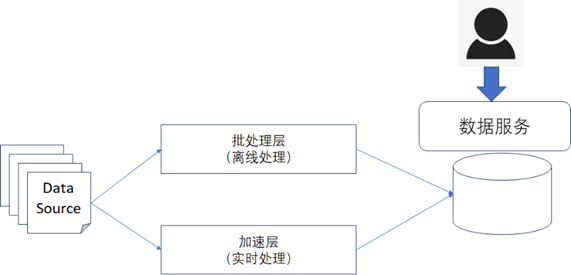
从图中可以看到Lambda架构是将离线处理和实时处理分开进行维护的,这就意味着需要开发和维护两套不同的数据处理代码,系统的复杂度很高,管理和维护的成本也很高。
Kappa架构其实可以看成是Lambda架构的优化和改进,在Kappa架构中实时任务需要承担全部数据的处理,会让实时任务处理的压力较大,但是Kappa架构将实时代码和离线代码进行了统一,方便了代码进行管理和维护也让数据的口径保持了统一,同时也降低了维护两套代码的工作量。
相比于Lambda架构,Kappa架构最大的问题在于一旦需要对历史数据进行重新处理,那么Kappa架构将难以实现,因为Kappa架构通常所使用的都是实时流处理的技术组件,比如像Flink等,但是如果做历史数据处理时,可能像Flink这样的技术组件就难以胜任,而擅长做离线数据处理的类似Spark这样的技术组件会更加适合,但是Flink的代码和Spark的代码通常是无法做共用的。
从对Lambda架构和Kappa架构的对比分析来看,两者各有优点,也有缺点,在实际应用当中,可能还需要同时结合这两种架构的优缺点来设计最符合自身业务和需求的数据处理架构。通常建议如下:
1.3、数据存储层
数据存储层主要负责各种类型的数据的存储,在架构设计时,还需要综合考虑如下问题来制定数据存储的架构和策略。
数据存储的技术方案可以有很多选型,如下所示,通常需要根据实际的业务需要来进行综合的选择。
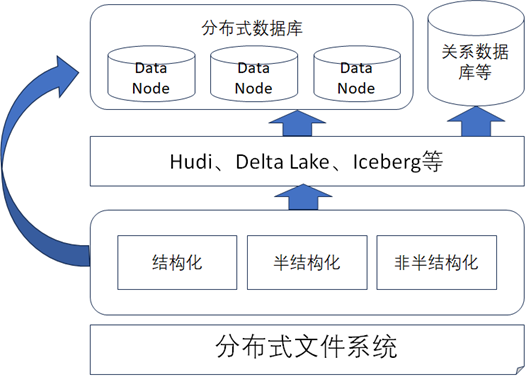
在开源社区中,常见的数据湖有Hudi、Delta Lake、Iceberg等。
通过以上分析,数据存储层的架构设计通常建议设计成当前最为流行的湖仓一体的架构,并且针对特殊的业务场景,可以引入一些分布式数据库或者关系型数据库进行辅助,如下图所示。
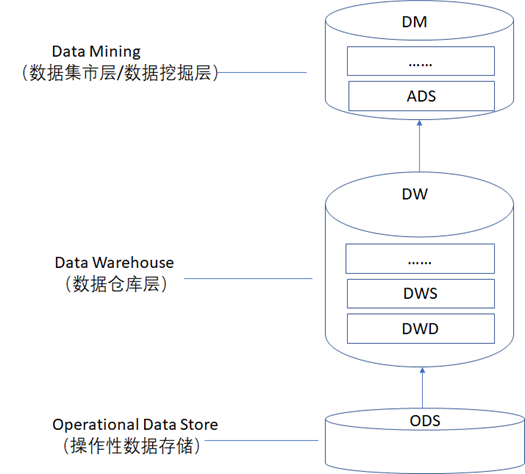
数据存储层在存储数据时,通常还会对数据进行分层存储,数据分层的架构实现方案通常如下图所示,数据分层主要是为了
1.4、数据管理层
数据管理层主要负责对数据进行分类、标识以及管理,主要会包含元数据管理、数据血缘跟踪管理、数据质量管理、数据权限和安全管理、数据监控和告警管理等,其总体的实现架构图如下图所示。
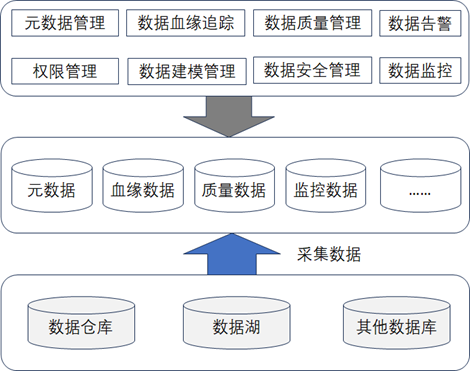
数据管理层的技术核心就是元数据、血缘数据、质量数据、监控数据等采集获取,我们在 清华大学出版社出版的 《数据资产管理核心技术与应用》一书的前面的章节中已经有过很具体的描述,在拿到这些数据后,数据管理层主要要实现的功能就是把这些数据做集成并且展示到数据资产管理平台中,数据管理层是数据资产管理的核心。
1.5、数据分析层
在数据分析层的架构设计中,主要包含如下两个部分:
| BI 工具名称 |
描述 |
适用的场景 |
| Power BI |
是由微软推出的一款BI数据分析工具 |
成本较高,通常适合于微软云相关的服务中使用 |
| Pentaho |
开源的BI分析工具,具有数据整合、报表生成和数据可视化等功能 |
开源产品。适合于自己有部署和运维能力的团队进行使用 |
| Quick BI
|
是阿里云推出的一款BI数据分析工具 |
由于是阿里云推出,所以通常只适合于阿里云中使用。 |
| FineBI |
是由帆软推出的一款BI数据分析工具 |
商业软件,一般需要购买,通常适用于政府或者企事业单位使。 |
在选择BI的数据分析工具时,一般建议结合自身的业务需求、使用成本、管理维护成本等多个方面来综合考虑,然后再选择最合适的BI工具。
通过如上两点的分析,数据分析层的整体架构设计通常如下图所示。
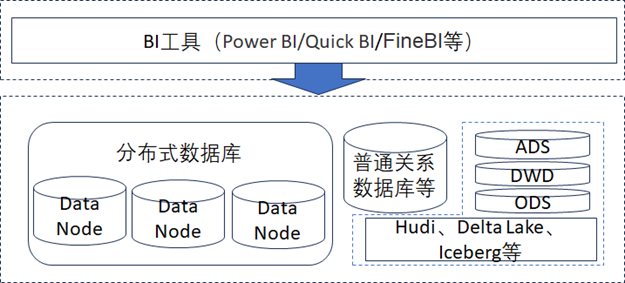
1.6、数据服务层
数据服务层通常是让数据对外提供服务,让数据可以服务于业务,并且负责对数据服务进行管理,数据服务层通常的架构实现如下图所示,数据服务的具体技术实现细节可以参考清华大学出版社出版的《数据资产管理核心技术与应用》一书的第六章。
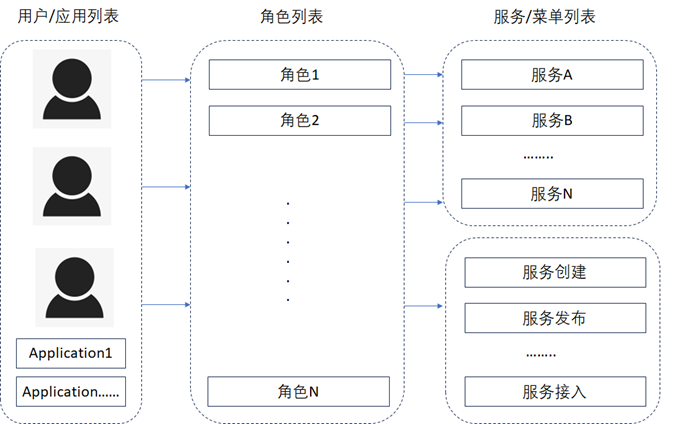
数据服务层在设计时,通常需要包括服务创建、服务发布,服务接入、服务降级、服务熔断、服务监控以及权限管理等模块,对于服务访问的权限管理通常建议也可以采用基于角色的访问控制 (RBAC)来实现,如下图所示。
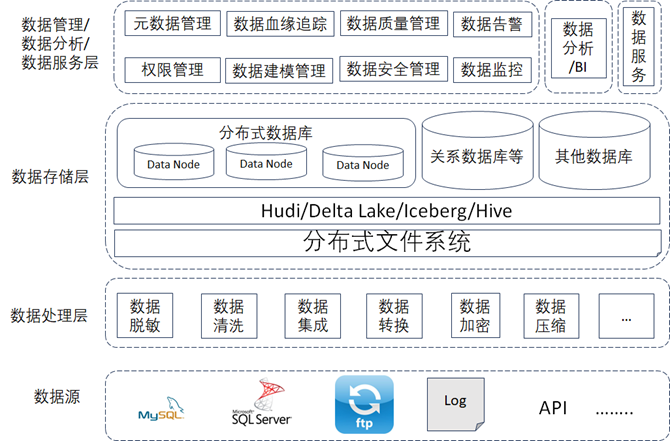
通过对每一层做架构分析与设计后,得到最终如下图所示的数据资产架构图,这是大数据处理中最常见的架构设计方案,解决了数据的可扩展性以及对于不管什么类型或者什么什么格式的数据,都可以做数据处理、存储以及分析。
《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,全书共分10章,第1章主要让读者认识数据资产,了解数据资产相关的基础概念,以及数据资产的发展情况。第2~8章主要介绍大数据时代数据资产管理所涉及的核心技术,内容包括元数据的采集与存储、数据血缘、数据质量、数据监控与告警、数据服务、数据权限与安全、数据资产管理架构等。第9~10章主要从实战的角度介绍数据资产管理技术的应用实践,包括如何对元数据进行管理以发挥出数据资产的更大潜力,以及如何对数据进行建模以挖掘出数据中更大的价值。
 官方公众号
官方公众号