ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录

本工具设计的初衷是用来获取微信账号的相关信息并解析PC版微信的数据库。
程序以 Python 语言开发,可读取、解密、还原微信数据库并帮助用户查看聊天记录,还可以将其聊天记录导出为csv、html等格式用于AI训练,自动回复或备份等等作用。下面我们将深入探讨这个工具的各个方面及其工作原理。
本项目仅供学习交流使用,严禁用于商业用途或非法途径,任何违反法律法规、侵犯他人合法权益的行为,均与本项目及其开发者无关,后果由行为人自行承担。
【完整演示工具下载】
https://www.chwm.vip/index.html?aid=23
我们上一篇文章《劫持微信聊天记录并分析还原 —— 合并解密后的数据库(三)》已经讲解了如何将解密后的微信数据库合并成一整个.db文件,那么本次我们将详细介绍一下微信数据库的结构与各个数据库的作用。
说明:针对 .../WeChat Files/wxid_xxxxxxxx/Msg下的各个文件解密后的内容进行概述。
未作特别说明的情况下,“聊天记录数据”指代的数据结构上都和Multi文件夹中的完整聊天记录数据相同或类似。
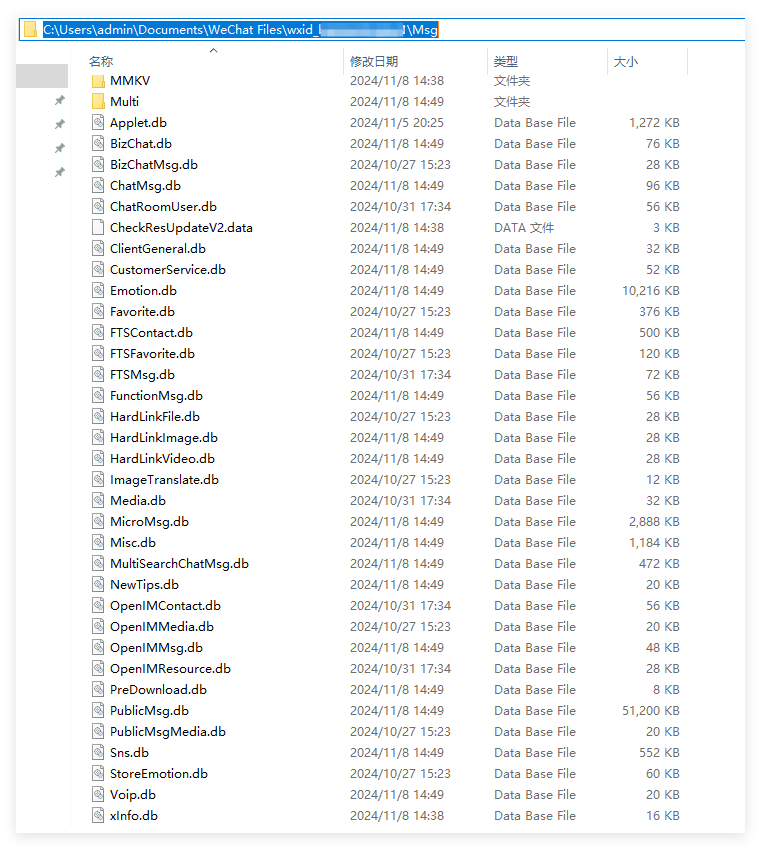
微信小程序的相关数据,包括但不限于:
你使用过的小程序 RecentWxApp
星标的小程序 StarWxApp
各个小程序的基本信息 WAContact
用处不大,不过可以看到你使用过的小程序的名称和图标,以及小程序的AppID
企业微信联系人数据,包括但不限于:
在微信中可以访问的企业微信会话ChatInfo
一部分会话的信息ChatSession(未确认与ChatInfo的关系;这其中的Content字段是最近一条消息,疑似用于缓存展示的内容)
包括群聊在内的聊天涉及的所有企业微信用户身份信息UsrInfo
该微信账号绑定的企业微信身份MyUsrInfo
特别说明:未经详细查证,这其中的聊天是否包含使用普通微信身份与企业微信用户发起的聊天,还是只包含使用绑定到普通微信的企业微信身份与其它企业微信身份发起的聊天。
企业微信聊天记录数据,包括所有和企业微信聊天的数据。
与BizChat一样,未确定涉及的范围究竟是只有企业微信-企业微信还是同时包含普通微信-企业微信。
另外,此处的消息与Multi文件夹中真正的微信消息不同的是在于没有拆分数据库。
这个也是企业微信的数据,包括联系人、企业信息、与企业微信联系人的消息等。
这个是普通微信-企业微信的数据,上面biz前缀的是企业微信-企业微信
这个不常用,而且也没有全新的数据结构,不再详细说了。
顾名思义表情包相关,包括但不限于以下内容:
CustomEmotion:顾名思义用户手动上传的GIF表情,包含下载链接,不过看起来似乎有加密(内有aesKey字段但我没测试)
EmotionDes1 和 EmotionItem 应该也是类似的内容,没仔细研究
EmotionPackageItem:账号添加的表情包的集合列表(从商店下载的那种)
ps:用处不大,微信的MSG文件夹有表情包的url链接,可以直接网络获取聊天记录中的表情包。
FavItems:收藏的消息条目列表
FavDataItem:收藏的具体数据。大概可以确定以下两点
即使只是简单收藏一篇公众号文章也会在 FavDataItem 中有一个对应的记录
对于收藏的合并转发类型的消息,合并转发中的每一条消息在 FavDataItem 中都是一个独立的记录
FavTags:为收藏内容添加的标签
微信朋友圈的相关数据:
FeedsV20:朋友圈的XML数据
CommentV20:朋友圈点赞或评论记录
NotificationV7:朋友圈通知
SnsConfigV20:一些配置信息,能读懂的是其中有你的朋友圈背景图
SnsGroupInfoV5:猜测是旧版微信朋友圈可见范围的可见或不可见名单
有一堆表
搜索收藏内容的索引
ps:对于收藏内容通过文字搜索,电脑版是把所有东西拼接成一个超长字符串来实现的。这对于文本、链接等没啥问题,但是对于合并转发消息,就会出现搜索[图片] 这一关键词。
这个数据库前缀不一样,但是看内容和结构应该还是一个搜索相关,搜索的是聊天记录中的文件
存储了文件名和其所在的聊天
不过FTSMsgSearch18_content和SessionAttachInfo两张表记录数量有显著差异,不确定是哪个少了或是怎样。
一个数据库,不应该和分类平级,但是我认为这是分析到目前以来最核心的,因此单独来说了。
一些软件的介绍,猜测可能是关于某些直接从手机APP跳转到微信的转发会带有的转发来源小尾巴的信息
与公众号相关的内容,应该主要是账号本身相关。
能确定的是 BizSessionNewFeeds 这张表保存的是订阅号大分类底下的会话信息,包括头像、最近一条推送等。
保存“聊天”列表中每个会话最后一次标记已读的时间
存储群聊相关信息
ChatRoom:存储每个群聊的用户列表(包括微信号列表和群昵称列表)和个人群昵称等信息
ChatRoomInfo:群聊相关信息,主要是群公告内容,与成员无关 顺便再吐槽一下,微信这个位置有一个命名出现异常的,别的表前缀都是ChatRoom,而突然出现一个ChatroomTool
顾名思义,联系人。不过这里的联系人并不是指你的好友,而是所有你可能看见的人,除好友外还有所有群聊中的所有陌生人。
Contact:这张表存储的是用户基本信息,包括但不限于微信号(没有好友的陌生人也能看!)、昵称、备注名、设置的标签等等,甚至还有生成的各种字段的拼音,可能是用于方便搜索的吧
ContactHeadImgUrl:头像地址
ContactLabel:好友标签 ID 与名称对照
ExtraBuf: 存储位置信息、手机号、邮箱等信息
存了一部分好友的拍一拍后缀,但是只有几个,我记得我电脑上显示过的拍一拍似乎没有这么少?
真正的“聊天”栏目显示的会话列表,一个不多一个不少,包括“折叠的群聊”这样子的特殊会话;信息包括名称、未读消息数、最近一条消息等
这张表在我这里有百余条数据,但是我实在没搞明白它是什么
FTS 这一前缀了——这代表的是搜索时所需的索引。
其内主要的内容是这样的两张表:
FTSChatMsg2_content:内有三个字段
docid:从1开始递增的数字,相当于当前条目的 ID
c0content:搜索关键字(在微信搜索框输入的关键字被这个字段包含的内容可以被搜索到)
c1entityId:尚不明确用途,可能是校验相关
FTSChatMsg2_MetaData
docid:与FTSChatMsg2_content表中的 docid 对应
msgId:与MSG数据库中的内容对应
entityId:与FTSChatMsg2_content表中的 c1entityId 对应
type:可能是该消息的类型
其余字段尚不明确
特别地,表名中的这个数字2,个人猜测可能是当前数据库格式的版本号。
这里存储了所有的语音消息。数据库中有且仅有Media一张表,内含三个有效字段:
Key
Reserved0 与MSG数据库中消息的MsgSvrID一一对应
Buf silk格式的语音数据
内部主要的两个表是 MSG 和 Name2ID
Name2ID 这张表只有一列,内容格式是微信号或群聊ID@chatroom
作用是使MSG中的某些字段与之对应。虽然表中没有 ID 这一列,但事实上微信默认了第几行 ID 就是几(从1开始编号)。
localId:字面意思消息在本地的 ID,暂未发现其功用
TalkerId:消息所在房间的 ID(该信息为猜测,猜测原因见 StrTalker 字段),与Name2ID对应。
MsgSvrID:猜测 Srv 可能是 Server 的缩写,代指服务器端存储的消息 ID
Type:消息类型,具体对照见表1
SubType:消息类型子分类,暂时未见其实际用途
IsSender:是否是自己发出的消息,也就是标记消息展示在对话页左边还是右边,取值0或1
CreateTime:消息创建时间的秒级时间戳。此处需要进一步实验来确认该时间具体标记的是哪个时间节点,个人猜测的规则如下:
从这台电脑上发出的消息:标记代表的是每个消息点下发送按钮的那一刻
从其它设备上发出的/收到的来自其它用户的消息:标记的是本地从服务器接收到这一消息的时间
Sequence:次序,虽然看起来像一个毫秒级时间戳但其实不是。这是 CreateTime 字段末尾接上三位数字组成的,通常情况下为000,如果在出现两条 CreateTime 相同的消息则最后三位依次递增。需要进一步确认不重复范围是在一个会话内还是所有会话。 CreateTime 相同的消息则最后三位依次递增。需要进一步确认不重复范围是在一个会话内还是所有会话。
StatusEx、FlagEx、Status、MsgServerSeq、MsgSequence:这五个字段个人暂时没有分析出有效信息
StrTalker:消息发送者的微信号。特别说明,从这里来看的话,上面的 TalkerId 字段大概率是指的消息所在的房间ID,而非发送者ID,当然也可能和 TalkerId 属于重复内容,这一点待确认。
StrContent:字符串格式的数据。特别说明的是,除了文本类型的消息外,别的大多类型这一字段都会是一段 XML 数据标记一些相关信息。通过解析xml可以得到更多的信息,例如图片的宽高、语音的时长等等。
DisplayContent:对于拍一拍,保存拍者和被拍者账号信息
Reserved0~6:这些字段也还没有分析出有效信息,也有的字段恒为空
CompressContent:字面意思是压缩的数据,实际上也就是微信任性不想存在 StrContent 里的数据在这里(例如带有引用的文本消息等;采用lz4压缩算法压缩)
BytesExtra:额外的二进制格式数据
BytesTrans:目前看这是一个恒为空的字段
表1:MSG.Type字段数值与含义对照表(可能可以扩展到其它数据库中同样标记消息类型这一信息的字段)
| 分类Type | 子分类SubType | 对应类型 |
|---|---|---|
| 1 | 0 | 文本 |
| 3 | 0 | 图片 |
| 34 | 0 | 语音 |
| 43 | 0 | 视频 |
| 47 | 0 | 动画表情(第三方开发的表情包) |
| 49 | 1 | 类似文字消息而不一样的消息,目前只见到一个阿里云盘的邀请注册是这样的。估计和57子类的情况一样 |
| 49 | 5 | 卡片式链接,CompressContent 中有标题、简介等,BytesExtra 中有本地缓存的封面路径 |
| 49 | 6 | 文件,CompressContent 中有文件名和下载链接(但不会读),BytesExtra 中有本地保存的路径 |
| 49 | 8 | 用户上传的 GIF 表情,CompressContent 中有CDN链接,不过似乎不能直接访问下载 |
| 49 | 19 | 合并转发的聊天记录,CompressContent 中有详细聊天记录,BytesExtra 中有图片视频等的缓存 |
| 49 | 33/36 | 分享的小程序,CompressContent 中有卡片信息,BytesExtra 中有封面缓存位置 |
| 49 | 57 | 带有引用的文本消息(这种类型下 StrContent 为空,发送和引用的内容均在 CompressContent 中) |
| 49 | 63 | 视频号直播或直播回放等 |
| 49 | 87 | 群公告 |
| 49 | 88 | 视频号直播或直播回放等 |
| 49 | 2000 | 转账消息(包括发出、接收、主动退还) |
| 49 | 2003 | 赠送红包封面 |
| 10000 | 0 | 系统通知(居中出现的那种灰色文字) |
| 10000 | 4 | 拍一拍 |
| 10000 | 8000 | 系统通知(特别包含你邀请别人加入群聊) |
微信PC端各个数据库文件结构与功能简述 - 根目录_微信电脑端目录格式
以下是各个数据库的处理实现代码:
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: dbbase.py
# Description:
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
import importlib
import os
import sqlite3
import time
from .utils import db_loger
from dbutils.pooled_db import PooledDB
# import logging
#
# db_loger = logging.getLogger("db_prepare")
class DatabaseSingletonBase:
# _singleton_instances = {} # 使用字典存储不同db_path对应的单例实例
_class_name = "DatabaseSingletonBase"
_db_pool = {} # 使用字典存储不同db_path对应的连接池
# def __new__(cls, *args, **kwargs):
# if cls._class_name not in cls._singleton_instances:
# cls._singleton_instances[cls._class_name] = super().__new__(cls)
# return cls._singleton_instances[cls._class_name]
@classmethod
def connect(cls, db_config):
"""
连接数据库,如果增加其他数据库连接,则重写该方法
:param db_config: 数据库配置
:return: 连接池
"""
if not db_config:
raise ValueError("db_config 不能为空")
db_key = db_config.get("key", "chwm.vip")
db_type = db_config.get("type", "sqlite")
if db_key in cls._db_pool and cls._db_pool[db_key] is not None:
return cls._db_pool[db_key]
if db_type == "sqlite":
db_path = db_config.get("path", "")
if not os.path.exists(db_path):
raise FileNotFoundError(f"文件不存在: {db_path}")
pool = PooledDB(
creator=sqlite3, # 使用 sqlite3 作为连接创建者
maxconnections=0, # 连接池最大连接数
mincached=4, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxusage=1, # 一个链接最多被重复使用的次数,None表示无限制
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
ping=0, # ping 数据库判断是否服务正常
database=db_path
)
elif db_type == "mysql":
mysql_config = {
'user': db_config['user'],
'host': db_config['host'],
'password': db_config['password'],
'database': db_config['database'],
'port': db_config['port']
}
pool = PooledDB(
creator=importlib.import_module('pymysql'), # 使用 mysql 作为连接创建者
ping=1, # ping 数据库判断是否服务正常
**mysql_config
)
else:
raise ValueError(f"不支持的数据库类型: {db_type}")
db_loger.info(f"{pool} 连接句柄创建 {db_config}")
cls._db_pool[db_key] = pool
return pool
class DatabaseBase(DatabaseSingletonBase):
_class_name = "DatabaseBase"
existed_tables = []
def __init__(self, db_config):
"""
db_config = {
"key": "test1",
"type": "sqlite",
"path": r"C:\***\wxdump_work\merge_all.db"
}
"""
self.config = db_config
self.pool = self.connect(self.config)
self.__get_existed_tables()
def __get_existed_tables(self):
sql = "SELECT tbl_name FROM sqlite_master WHERE type = 'table' and tbl_name!='sqlite_sequence';"
existing_tables = self.execute(sql)
if existing_tables:
self.existed_tables = [row[0].lower() for row in existing_tables]
return self.existed_tables
else:
return None
def tables_exist(self, required_tables: str or list):
"""
判断该类所需要的表是否存在
Check if all required tables exist in the database.
Args:
required_tables (list or str): A list of table names or a single table name string.
Returns:
bool: True if all required tables exist, False otherwise.
"""
if isinstance(required_tables, str):
required_tables = [required_tables]
rbool = all(table.lower() in self.existed_tables for table in (required_tables or []))
if not rbool: db_loger.warning(f"{required_tables=}\n{self.existed_tables=}\n{rbool=}")
return rbool
def execute(self, sql, params=None):
"""
执行SQL语句
:param sql: SQL语句 (str)
:param params: 参数 (tuple)
:return: 查询结果 (list)
"""
connection = self.pool.connection()
try:
# connection.text_factory = bytes
cursor = connection.cursor()
if params:
cursor.execute(sql, params)
else:
cursor.execute(sql)
return cursor.fetchall()
except Exception as e1:
try:
connection.text_factory = bytes
cursor = connection.cursor()
if params:
cursor.execute(sql, params)
else:
cursor.execute(sql)
rdata = cursor.fetchall()
connection.text_factory = str
return rdata
except Exception as e2:
db_loger.error(f"{sql=}\n{params=}\n{e1=}\n{e2=}\n", exc_info=True)
return None
finally:
connection.close()
def close(self):
self.pool.close()
db_loger.info(f"关闭数据库 - {self.config}")
def __del__(self):
self.close()
# class MsgDb(DatabaseBase):
#
# def p(self, *args, **kwargs):
# sel = "select tbl_name from sqlite_master where type='table'"
# data = self.execute(sel)
# # print([i[0] for i in data])
# return data
#
#
# class MsgDb1(DatabaseBase):
# _class_name = "MsgDb1"
#
# def p(self, *args, **kwargs):
# sel = "select tbl_name from sqlite_master where type='table'"
# data = self.execute(sel)
# # print([i[0] for i in data])
# return data
#
#
# if __name__ == '__main__':
# logging.basicConfig(level=logging.INFO,
# style='{',
# datefmt='%Y-%m-%d %H:%M:%S',
# format='[{levelname[0]}] {asctime} [{name}:{levelno}] {pathname}:{lineno} {message}'
# )
#
# config1 = {
# "key": "test1",
# "type": "sqlite",
# "path": r"D:\e_all.db"
# }
# config2 = {
# "key": "test2",
# "type": "sqlite",
# "path": r"D:\_call.db"
# }
#
# t1 = MsgDb(config1)
# t1.p()
# t2 = MsgDb(config2)
# t2.p()
# t3 = MsgDb1(config1)
# t3.p()
# t4 = MsgDb1(config2)
# t4.p()
#
# print(t4._db_pool)
# # 销毁t1
# del t1
# # 销毁t2
# del t2
# del t3
#
# # 销毁t4
# del t4
# import time
# time.sleep(1)
#
# t1 = MsgDb(config1)
# t1.p()
# t2 = MsgDb(config2)
# t2.p()
#
#
# print(t2._db_pool)
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: Favorite.py
# Description: 负责处理wx收藏数据库
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
from collections import defaultdict
from .dbbase import DatabaseBase
from .utils import timestamp2str, xml2dict
# * FavItems:收藏的消息条目列表
# * FavDataItem:收藏的具体数据。大概可以确定以下两点
# * 即使只是简单收藏一篇公众号文章也会在 FavDataItem 中有一个对应的记录
# * 对于收藏的合并转发类型的消息,合并转发中的每一条消息在 FavDataItem 中都是一个独立的记录
# * FavTags:为收藏内容添加的标签
class FavoriteHandler(DatabaseBase):
_class_name = "Favorite"
Favorite_required_tables = ["FavItems", "FavDataItem", "FavTagDatas", "FavBindTagDatas"]
def get_tags(self, LocalID):
"""
return: {LocalID: TagName}
"""
if not self.tables_exist("FavTagDatas"):
return {}
if LocalID is None:
sql = "select LocalID, TagName from FavTagDatas order by ServerSeq"
else:
sql = "select LocalID, TagName from FavTagDatas where LocalID = '%s' order by ServerSeq " % LocalID
tags = self.execute(sql) # [(1, 797940830, '程序语言类'), (2, 806153863, '账单')]
# 转换为字典
tags = {tag[0]: tag[1] for tag in tags}
return tags
def get_FavBindTags(self):
"""
return: [(FavLocalID, TagName)]
"""
sql = ("select DISTINCT A.FavLocalID, B.TagName "
"from FavBindTagDatas A, FavTagDatas B where A.TagLocalID = B.LocalID")
FavBindTags = self.execute(sql)
return FavBindTags
def get_favorite(self):
"""
return: [{FavItemsFields}, {FavItemsFields}]
"""
FavItemsFields = {
"FavLocalID": "本地收藏ID",
"SvrFavId": "服务器收藏ID",
"SourceId": "源ID",
"Type": "类型",
"SourceType": "源类型",
"LocalStatus": "本地状态",
"Flag": "标记",
"Status": "状态",
"FromUser": "源用户",
"RealChatName": "实际聊天名称",
"SearchKey": "搜索关键字",
"UpdateTime": "更新时间",
"reseverd0": "预留字段0",
"XmlBuf": "XML缓冲区"
}
FavDataItemFields = {
"FavLocalID": "本地收藏ID",
"Type": "类型",
"DataId": "数据ID",
"HtmlId": "HTML ID",
"Datasourceid": "数据源ID",
"Datastatus": "数据状态",
"Datafmt": "数据格式",
"Datatitle": "数据标题",
"Datadesc": "数据描述",
"Thumbfullmd5": "缩略图全MD5",
"Thumbhead256md5": "缩略图头256MD5",
"Thumbfullsize": "缩略图全尺寸",
"fullmd5": "全MD5",
"head256md5": "头256MD5",
"fullsize": "全尺寸",
"cdn_thumburl": "CDN缩略图URL",
"cdn_thumbkey": "CDN缩略图KEY",
"thumb_width": "缩略图宽度",
"thumb_height": "缩略图高度",
"cdn_dataurl": "CDN数据URL",
"cdn_datakey": "CDN数据KEY",
"cdn_encryver": "CDN加密版本",
"duration": "时长",
"stream_weburl": "流媒体WEB URL",
"stream_dataurl": "流媒体数据URL",
"stream_lowbandurl": "流媒体低带宽URL",
"sourcethumbpath": "源缩略图路径",
"sourcedatapath": "源数据路径",
"stream_videoid": "流媒体视频ID",
"Rerserved1": "保留字段1",
"Rerserved2": "保留字段2",
"Rerserved3": "保留字段3",
"Rerserved4": "保留字段4",
"Rerserved5": "保留字段5",
"Rerserved6": "保留字段6",
"Rerserved7": "保留字段7"
}
if not self.tables_exist(["FavItems", "FavDataItem"]):
return False
sql1 = "select " + ",".join(FavItemsFields.keys()) + " from FavItems order by UpdateTime desc"
sql2 = "select " + ",".join(FavDataItemFields.keys()) + " from FavDataItem B order by B.RecId asc"
FavItemsList = self.execute(sql1)
FavDataItemList = self.execute(sql2)
if FavItemsList is None or len(FavItemsList) == 0:
return False
FavDataDict = {}
if FavDataItemList and len(FavDataItemList) >= 0:
for item in FavDataItemList:
data_dict = {}
for i, key in enumerate(FavDataItemFields.keys()):
data_dict[key] = item[i]
FavDataDict[item[0]] = FavDataDict.get(item[0], []) + [data_dict]
# 获取标签
FavTags = self.get_FavBindTags()
FavTagsDict = {}
for FavLocalID, TagName in FavTags:
FavTagsDict[FavLocalID] = FavTagsDict.get(FavLocalID, []) + [TagName]
rdata = []
for item in FavItemsList:
processed_item = {
key: item[i] for i, key in enumerate(FavItemsFields.keys())
}
processed_item['UpdateTime'] = timestamp2str(processed_item['UpdateTime'])
processed_item['XmlBuf'] = xml2dict(processed_item['XmlBuf'])
processed_item['TypeName'] = Favorite_type_converter(processed_item['Type'])
processed_item['FavData'] = FavDataDict.get(processed_item['FavLocalID'], [])
processed_item['Tags'] = FavTagsDict.get(processed_item['FavLocalID'], [])
rdata.append(processed_item)
try:
import pandas as pd
except ImportError:
return False
pf = pd.DataFrame(FavItemsList)
pf.columns = FavItemsFields.keys() # set column names
pf["UpdateTime"] = pf["UpdateTime"].apply(timestamp2str) # 处理时间
pf["XmlBuf"] = pf["XmlBuf"].apply(xml2dict) # 处理xml
pf["TypeName"] = pf["Type"].apply(Favorite_type_converter) # 添加类型名称列
pf["FavData"] = pf["FavLocalID"].apply(lambda x: FavDataDict.get(x, [])) # 添加数据列
pf["Tags"] = pf["FavLocalID"].apply(lambda x: FavTagsDict.get(x, [])) # 添加标签列
pf = pf.fillna("") # 去掉Nan
rdata = pf.to_dict(orient="records")
return rdata
def Favorite_type_converter(type_id_or_name: [str, int]):
"""
收藏类型ID与名称转换
名称(str)=>ID(int)
ID(int)=>名称(str)
:param type_id_or_name: 消息类型ID或名称
:return: 消息类型名称或ID
"""
type_name_dict = defaultdict(lambda: "未知", {
1: "文本", # 文本 已测试
2: "图片", # 图片 已测试
3: "语音", # 语音
4: "视频", # 视频 已测试
5: "链接", # 链接 已测试
6: "位置", # 位置
7: "小程序", # 小程序
8: "文件", # 文件 已测试
14: "聊天记录", # 聊天记录 已测试
16: "群聊视频", # 群聊中的视频 可能
18: "笔记" # 笔记 已测试
})
if isinstance(type_id_or_name, int):
return type_name_dict[type_id_or_name]
elif isinstance(type_id_or_name, str):
return next((k for k, v in type_name_dict.items() if v == type_id_or_name), (0, 0))
else:
raise ValueError("Invalid input type")
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: MediaMSG.py
# Description: 负责处理语音数据库
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
from .dbbase import DatabaseBase
from .utils import silk2audio
class MediaHandler(DatabaseBase):
_class_name = "MediaMSG"
Media_required_tables = ["Media"]
def Media_add_index(self):
"""
添加索引, 加快查询速度
"""
if self.tables_exist("Media"):
self.execute("CREATE INDEX IF NOT EXISTS MsgSvrID ON Media(Reserved0)")
def get_audio(self, MsgSvrID, is_play=False, is_wave=False, save_path=None, rate=24000):
if not self.tables_exist("Media"):
return False
sql = "select Buf from Media where Reserved0=? "
DBdata = self.execute(sql, (MsgSvrID,))
if not DBdata:
return False
if len(DBdata) == 0:
return False
data = DBdata[0][0] # [1:] + b'\xFF\xFF'
try:
pcm_data = silk2audio(buf_data=data, is_play=is_play, is_wave=is_wave, save_path=save_path, rate=rate)
return pcm_data
except Exception as e:
return False
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: MicroMsg.py
# Description: 负责处理联系人数据库
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
import logging
from .dbbase import DatabaseBase
from .utils import timestamp2str, bytes2str, db_loger, db_error
import blackboxprotobuf
class MicroHandler(DatabaseBase):
_class_name = "MicroMsg"
Micro_required_tables = ["ContactLabel", "Contact", "ContactHeadImgUrl", "Session", "ChatInfo", "ChatRoom",
"ChatRoomInfo"]
def Micro_add_index(self):
"""
添加索引, 加快查询速度
"""
# 为 Session 表添加索引
if self.tables_exist("Session"):
self.execute("CREATE INDEX IF NOT EXISTS idx_Session_strUsrName_nTime ON Session(strUsrName, nTime);")
self.execute("CREATE INDEX IF NOT EXISTS idx_Session_nOrder ON Session(nOrder);")
self.execute("CREATE INDEX IF NOT EXISTS idx_Session_nTime ON Session(nTime);")
# 为 Contact 表添加索引
if self.tables_exist("Contact"):
self.execute("CREATE INDEX IF NOT EXISTS idx_Contact_UserName ON Contact(UserName);")
# 为 ContactHeadImgUrl 表添加索引
if self.tables_exist('ContactHeadImgUrl'):
self.execute("CREATE INDEX IF NOT EXISTS idx_ContactHeadImgUrl_usrName ON ContactHeadImgUrl(usrName);")
# 为 ChatInfo 表添加索引
if self.tables_exist('ChatInfo'):
self.execute("CREATE INDEX IF NOT EXISTS idx_ChatInfo_Username_LastReadedCreateTime "
"ON ChatInfo(Username, LastReadedCreateTime);")
self.execute(
"CREATE INDEX IF NOT EXISTS idx_ChatInfo_LastReadedCreateTime ON ChatInfo(LastReadedCreateTime);")
# 为 Contact 表添加复合索引
if self.tables_exist('Contact'):
self.execute("CREATE INDEX IF NOT EXISTS idx_Contact_search "
"ON Contact(UserName, NickName, Remark, Alias, QuanPin, PYInitial, RemarkQuanPin, RemarkPYInitial);")
# 为 ChatRoom 和 ChatRoomInfo 表添加索引
if self.tables_exist(['ChatRoomInfo', "ChatRoom"]):
self.execute("CREATE INDEX IF NOT EXISTS idx_ChatRoom_ChatRoomName ON ChatRoom(ChatRoomName);")
self.execute("CREATE INDEX IF NOT EXISTS idx_ChatRoomInfo_ChatRoomName ON ChatRoomInfo(ChatRoomName);")
@db_error
def get_labels(self, id_is_key=True):
"""
读取标签列表
:param id_is_key: id_is_key: True: id作为key,False: name作为key
:return:
"""
labels = {}
if not self.tables_exist("ContactLabel"):
return labels
sql = "SELECT LabelId, LabelName FROM ContactLabel ORDER BY LabelName ASC;"
result = self.execute(sql)
if not result:
return labels
if id_is_key:
labels = {row[0]: row[1] for row in result}
else:
labels = {row[1]: row[0] for row in result}
return labels
@db_error
def get_session_list(self):
"""
获取会话列表
:return: 会话列表
"""
sessions = {}
if not self.tables_exist(["Session", "Contact", "ContactHeadImgUrl"]):
return sessions
sql = (
"SELECT S.strUsrName,S.nOrder,S.nUnReadCount, S.strNickName, S.nStatus, S.nIsSend, S.strContent, "
"S.nMsgLocalID, S.nMsgStatus, S.nTime, S.nMsgType, S.Reserved2 AS nMsgSubType, C.UserName, C.Alias, "
"C.DelFlag, C.Type, C.VerifyFlag, C.Reserved1, C.Reserved2, C.Remark, C.NickName, C.LabelIDList, "
"C.ChatRoomType, C.ChatRoomNotify, C.Reserved5, C.Reserved6 as describe, C.ExtraBuf, H.bigHeadImgUrl "
"FROM (SELECT strUsrName, MAX(nTime) AS MaxnTime FROM Session GROUP BY strUsrName) AS SubQuery "
"JOIN Session S ON S.strUsrName = SubQuery.strUsrName AND S.nTime = SubQuery.MaxnTime "
"left join Contact C ON C.UserName = S.strUsrName "
"LEFT JOIN ContactHeadImgUrl H ON C.UserName = H.usrName "
"WHERE S.strUsrName!='@publicUser' "
"ORDER BY S.nTime DESC;"
)
db_loger.info(f"get_session_list sql: {sql}")
ret = self.execute(sql)
if not ret:
return sessions
id2label = self.get_labels()
for row in ret:
(strUsrName, nOrder, nUnReadCount, strNickName, nStatus, nIsSend, strContent,
nMsgLocalID, nMsgStatus, nTime, nMsgType, nMsgSubType,
UserName, Alias, DelFlag, Type, VerifyFlag, Reserved1, Reserved2, Remark, NickName, LabelIDList,
ChatRoomType, ChatRoomNotify, Reserved5, describe, ExtraBuf, bigHeadImgUrl) = row
ExtraBuf = get_ExtraBuf(ExtraBuf)
LabelIDList = LabelIDList.split(",") if LabelIDList else []
LabelIDList = [id2label.get(int(label_id), label_id) for label_id in LabelIDList if label_id]
nTime = timestamp2str(nTime) if nTime else None
sessions[strUsrName] = {
"wxid": strUsrName, "nOrder": nOrder, "nUnReadCount": nUnReadCount, "strNickName": strNickName,
"nStatus": nStatus, "nIsSend": nIsSend, "strContent": strContent, "nMsgLocalID": nMsgLocalID,
"nMsgStatus": nMsgStatus, "nTime": nTime, "nMsgType": nMsgType, "nMsgSubType": nMsgSubType,
"LastReadedCreateTime": nTime,
"nickname": NickName, "remark": Remark, "account": Alias,
"describe": describe, "headImgUrl": bigHeadImgUrl if bigHeadImgUrl else "",
"ExtraBuf": ExtraBuf, "LabelIDList": tuple(LabelIDList)
}
return sessions
@db_error
def get_recent_chat_wxid(self):
"""
获取最近聊天的联系人
:return: 最近聊天的联系人
"""
users = []
if not self.tables_exist(["ChatInfo"]):
return users
sql = (
"SELECT A.Username, LastReadedCreateTime, LastReadedSvrId "
"FROM ( SELECT Username, MAX(LastReadedCreateTime) AS MaxLastReadedCreateTime FROM ChatInfo "
"WHERE LastReadedCreateTime IS NOT NULL AND LastReadedCreateTime > 1007911408000 GROUP BY Username "
") AS SubQuery JOIN ChatInfo A "
"ON A.Username = SubQuery.Username AND LastReadedCreateTime = SubQuery.MaxLastReadedCreateTime "
"ORDER BY A.LastReadedCreateTime DESC;"
)
db_loger.info(f"get_recent_chat_wxid sql: {sql}")
result = self.execute(sql)
if not result:
return []
for row in result:
# 获取用户名、昵称、备注和聊天记录数量
username, LastReadedCreateTime, LastReadedSvrId = row
LastReadedCreateTime = timestamp2str(LastReadedCreateTime) if LastReadedCreateTime else None
users.append(
{"wxid": username, "LastReadedCreateTime": LastReadedCreateTime, "LastReadedSvrId": LastReadedSvrId})
return users
@db_error
def get_user_list(self, word: str = None, wxids: list = None, label_ids: list = None):
"""
获取联系人列表
[ 注意:如果修改这个函数,要同时修改dbOpenIMContact.py中的get_im_user_list函数 ]
:param word: 查询关键字,可以是wxid,用户名、昵称、备注、描述,允许拼音
:param wxids: wxid列表
:param label_ids: 标签id
:return: 联系人字典
"""
if isinstance(wxids, str):
wxids = [wxids]
if isinstance(label_ids, str):
label_ids = [label_ids]
users = {}
if not self.tables_exist(["Contact", "ContactHeadImgUrl"]):
return users
sql = (
"SELECT A.UserName, A.Alias, A.DelFlag, A.Type, A.VerifyFlag, A.Reserved1, A.Reserved2,"
"A.Remark, A.NickName, A.LabelIDList, A.ChatRoomType, A.ChatRoomNotify, A.Reserved5,"
"A.Reserved6 as describe, A.ExtraBuf, B.bigHeadImgUrl "
"FROM Contact A LEFT JOIN ContactHeadImgUrl B ON A.UserName = B.usrName WHERE 1==1 ;"
)
if word:
sql = sql.replace(";",
f"AND ( A.UserName LIKE '%{word}%' "
f"OR A.NickName LIKE '%{word}%' "
f"OR A.Remark LIKE '%{word}%' "
f"OR A.Alias LIKE '%{word}%' "
f"OR LOWER(A.QuanPin) LIKE LOWER('%{word}%') "
f"OR LOWER(A.PYInitial) LIKE LOWER('%{word}%') "
f"OR LOWER(A.RemarkQuanPin) LIKE LOWER('%{word}%') "
f"OR LOWER(A.RemarkPYInitial) LIKE LOWER('%{word}%') "
f") "
";")
if wxids:
sql = sql.replace(";", f"AND A.UserName IN ('" + "','".join(wxids) + "') ;")
if label_ids:
sql_label = [f"A.LabelIDList LIKE '%{i}%' " for i in label_ids]
sql_label = " OR ".join(sql_label)
sql = sql.replace(";", f"AND ({sql_label}) ;")
db_loger.info(f"get_user_list sql: {sql}")
result = self.execute(sql)
if not result:
return users
id2label = self.get_labels()
for row in result:
# 获取wxid,昵称,备注,描述,头像,标签
(UserName, Alias, DelFlag, Type, VerifyFlag, Reserved1, Reserved2, Remark, NickName, LabelIDList,
ChatRoomType, ChatRoomNotify, Reserved5, describe, ExtraBuf, bigHeadImgUrl) = row
ExtraBuf = get_ExtraBuf(ExtraBuf)
LabelIDList = LabelIDList.split(",") if LabelIDList else []
LabelIDList = [id2label.get(int(label_id), label_id) for label_id in LabelIDList if label_id]
# print(f"{UserName=}\n{Alias=}\n{DelFlag=}\n{Type=}\n{VerifyFlag=}\n{Reserved1=}\n{Reserved2=}\n"
# f"{Remark=}\n{NickName=}\n{LabelIDList=}\n{ChatRoomType=}\n{ChatRoomNotify=}\n{Reserved5=}\n"
# f"{describe=}\n{ExtraBuf=}\n{bigHeadImgUrl=}")
users[UserName] = {
"wxid": UserName, "nickname": NickName, "remark": Remark, "account": Alias,
"describe": describe, "headImgUrl": bigHeadImgUrl if bigHeadImgUrl else "",
"ExtraBuf": ExtraBuf, "LabelIDList": tuple(LabelIDList),
"extra": None}
extras = self.get_room_list(roomwxids=filter(lambda x: "@" in x, users.keys()))
for UserName in users:
users[UserName]["extra"] = extras.get(UserName, None)
return users
@db_error
def get_room_list(self, word=None, roomwxids: list = None):
"""
获取群聊列表
:param word: 群聊搜索词
:param roomwxids: 群聊wxid列表
:return: 群聊字典
"""
# 连接 MicroMsg.db 数据库,并执行查询
if isinstance(roomwxids, str):
roomwxids = [roomwxids]
rooms = {}
if not self.tables_exist(["ChatRoom", "ChatRoomInfo"]):
return rooms
sql = (
"SELECT A.ChatRoomName,A.UserNameList,A.DisplayNameList,A.ChatRoomFlag,A.IsShowName,"
"A.SelfDisplayName,A.Reserved2,A.RoomData, "
"B.Announcement,B.AnnouncementEditor,B.AnnouncementPublishTime "
"FROM ChatRoom A LEFT JOIN ChatRoomInfo B ON A.ChatRoomName==B.ChatRoomName "
"WHERE 1==1 ;")
if word:
sql = sql.replace(";",
f"AND A.ChatRoomName LIKE '%{word}%' ;")
if roomwxids:
sql = sql.replace(";", f"AND A.ChatRoomName IN ('" + "','".join(roomwxids) + "') ;")
db_loger.info(f"get_room_list sql: {sql}")
result = self.execute(sql)
if not result:
return rooms
for row in result:
# 获取用户名、昵称、备注和聊天记录数量
(ChatRoomName, UserNameList, DisplayNameList, ChatRoomFlag, IsShowName, SelfDisplayName,
Reserved2, RoomData,
Announcement, AnnouncementEditor, AnnouncementPublishTime) = row
UserNameList = UserNameList.split("^G")
DisplayNameList = DisplayNameList.split("^G")
RoomData = ChatRoom_RoomData(RoomData)
wxid2roomNickname = {}
if RoomData:
rd = []
for k, v in RoomData.items():
if isinstance(v, list):
rd += v
for i in rd:
try:
if isinstance(i, dict) and isinstance(i.get('1'), str) and i.get('2'):
wxid2roomNickname[i['1']] = i["2"]
except Exception as e:
db_loger.error(f"wxid2remark: ChatRoomName:{ChatRoomName}, {i} error:{e}", exc_info=True)
wxid2userinfo = self.get_user_list(wxids=UserNameList)
for i in wxid2userinfo:
wxid2userinfo[i]["roomNickname"] = wxid2roomNickname.get(i, "")
owner = wxid2userinfo.get(Reserved2, Reserved2)
rooms[ChatRoomName] = {
"wxid": ChatRoomName, "roomWxids": UserNameList, "IsShowName": IsShowName,
"ChatRoomFlag": ChatRoomFlag, "SelfDisplayName": SelfDisplayName,
"owner": owner, "wxid2userinfo": wxid2userinfo,
"Announcement": Announcement, "AnnouncementEditor": AnnouncementEditor,
"AnnouncementPublishTime": AnnouncementPublishTime}
return rooms
@db_error
def ChatRoom_RoomData(RoomData):
# 读取群聊数据,主要为 wxid,以及对应昵称
if RoomData is None or not isinstance(RoomData, bytes):
return None
data = get_BytesExtra(RoomData)
bytes2str(data) if data else None
return data
@db_error
def get_BytesExtra(BytesExtra):
if BytesExtra is None or not isinstance(BytesExtra, bytes):
return None
try:
deserialize_data, message_type = blackboxprotobuf.decode_message(BytesExtra)
return deserialize_data
except Exception as e:
db_loger.warning(f"\nget_BytesExtra: {e}\n{BytesExtra}", exc_info=True)
return None
@db_error
def get_ExtraBuf(ExtraBuf: bytes):
"""
读取ExtraBuf(联系人表)
:param ExtraBuf:
:return:
"""
if not ExtraBuf:
return None
buf_dict = {
'74752C06': '性别[1男2女]', '46CF10C4': '个性签名', 'A4D9024A': '国', 'E2EAA8D1': '省', '1D025BBF': '市',
'F917BCC0': '公司名称', '759378AD': '手机号', '4EB96D85': '企微属性', '81AE19B4': '朋友圈背景',
'0E719F13': '备注图片', '945f3190': '备注图片2',
'DDF32683': '0', '88E28FCE': '1', '761A1D2D': '2', '0263A0CB': '3', '0451FF12': '4', '228C66A8': '5',
'4D6C4570': '6', '4335DFDD': '7', 'DE4CDAEB': '8', 'A72BC20A': '9', '069FED52': '10', '9B0F4299': '11',
'3D641E22': '12', '1249822C': '13', 'B4F73ACB': '14', '0959EB92': '15', '3CF4A315': '16',
'C9477AC60201E44CD0E8': '17', 'B7ACF0F5': '18', '57A7B5A8': '19', '695F3170': '20', 'FB083DD9': '21',
'0240E37F': '22', '315D02A3': '23', '7DEC0BC3': '24', '16791C90': '25'
}
rdata = {}
for buf_name in buf_dict:
rdata_name = buf_dict[buf_name]
buf_name = bytes.fromhex(buf_name)
offset = ExtraBuf.find(buf_name)
if offset == -1:
rdata[rdata_name] = ""
continue
offset += len(buf_name)
type_id = ExtraBuf[offset: offset + 1]
offset += 1
if type_id == b"\x04":
rdata[rdata_name] = int.from_bytes(ExtraBuf[offset: offset + 4], "little")
elif type_id == b"\x18":
length = int.from_bytes(ExtraBuf[offset: offset + 4], "little")
rdata[rdata_name] = ExtraBuf[offset + 4: offset + 4 + length].decode("utf-16").rstrip("\x00")
elif type_id == b"\x17":
length = int.from_bytes(ExtraBuf[offset: offset + 4], "little")
rdata[rdata_name] = ExtraBuf[offset + 4: offset + 4 + length].decode("utf-8", errors="ignore").rstrip(
"\x00")
elif type_id == b"\x05":
rdata[rdata_name] = f"0x{ExtraBuf[offset: offset + 8].hex()}"
return rdata
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: MSG.py
# Description: 负责处理消息数据库数据
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
import json
import os
import re
import lz4.block
import blackboxprotobuf
from .dbbase import DatabaseBase
from .utils import db_error, timestamp2str, xml2dict, match_BytesExtra, type_converter
class MsgHandler(DatabaseBase):
_class_name = "MSG"
MSG_required_tables = ["MSG"]
def Msg_add_index(self):
"""
添加索引,加快查询速度
"""
# 检查是否存在索引
if not self.tables_exist("MSG"):
return
self.execute("CREATE INDEX IF NOT EXISTS idx_MSG_StrTalker ON MSG(StrTalker);")
self.execute("CREATE INDEX IF NOT EXISTS idx_MSG_CreateTime ON MSG(CreateTime);")
self.execute("CREATE INDEX IF NOT EXISTS idx_MSG_StrTalker_CreateTime ON MSG(StrTalker, CreateTime);")
@db_error
def get_m_msg_count(self, wxids: list = ""):
"""
获取聊天记录数量,根据wxid获取单个联系人的聊天记录数量,不传wxid则获取所有联系人的聊天记录数量
:param wxids: wxid list
:return: 聊天记录数量列表 {wxid: chat_count, total: total_count}
"""
if isinstance(wxids, str) and wxids:
wxids = [wxids]
if wxids:
wxids = "('" + "','".join(wxids) + "')"
sql = f"SELECT StrTalker, COUNT(*) FROM MSG WHERE StrTalker IN {wxids} GROUP BY StrTalker ORDER BY COUNT(*) DESC;"
else:
sql = f"SELECT StrTalker, COUNT(*) FROM MSG GROUP BY StrTalker ORDER BY COUNT(*) DESC;"
sql_total = f"SELECT COUNT(*) FROM MSG;"
if not self.tables_exist("MSG"):
return {}
result = self.execute(sql)
total_ret = self.execute(sql_total)
if not result:
return {}
total = 0
if total_ret and len(total_ret) > 0:
total = total_ret[0][0]
msg_count = {"total": total}
msg_count.update({row[0]: row[1] for row in result})
return msg_count
@db_error
def get_msg_list(self, wxids: list or str = "", start_index=0, page_size=500, msg_type: str = "",
msg_sub_type: str = "", start_createtime=None, end_createtime=None, my_talker="我"):
"""
获取聊天记录列表
:param wxids: [wxid]
:param start_index: 起始索引
:param page_size: 页大小
:param msg_type: 消息类型
:param msg_sub_type: 消息子类型
:param start_createtime: 开始时间
:param end_createtime: 结束时间
:param my_talker: 我
:return: 聊天记录列表 {"id": _id, "MsgSvrID": str(MsgSvrID), "type_name": type_name, "is_sender": IsSender,
"talker": talker, "room_name": StrTalker, "msg": msg, "src": src, "extra": {},
"CreateTime": CreateTime, }
"""
if not self.tables_exist("MSG"):
return [], []
if isinstance(wxids, str) and wxids:
wxids = [wxids]
param = ()
sql_wxid, param = (f"AND StrTalker in ({', '.join('?' for _ in wxids)}) ",
param + tuple(wxids)) if wxids else ("", param)
sql_type, param = ("AND Type=? ", param + (msg_type,)) if msg_type else ("", param)
sql_sub_type, param = ("AND SubType=? ", param + (msg_sub_type,)) if msg_type and msg_sub_type else ("", param)
sql_start_createtime, param = ("AND CreateTime>=? ", param + (start_createtime,)) if start_createtime else (
"", param)
sql_end_createtime, param = ("AND CreateTime<=? ", param + (end_createtime,)) if end_createtime else ("", param)
sql = (
"SELECT localId,TalkerId,MsgSvrID,Type,SubType,CreateTime,IsSender,Sequence,StatusEx,FlagEx,Status,"
"MsgSequence,StrContent,MsgServerSeq,StrTalker,DisplayContent,Reserved0,Reserved1,Reserved3,"
"Reserved4,Reserved5,Reserved6,CompressContent,BytesExtra,BytesTrans,Reserved2,"
"ROW_NUMBER() OVER (ORDER BY CreateTime ASC) AS id "
"FROM MSG WHERE 1=1 "
f"{sql_wxid}"
f"{sql_type}"
f"{sql_sub_type}"
f"{sql_start_createtime}"
f"{sql_end_createtime}"
f"ORDER BY CreateTime ASC LIMIT ?,?"
)
param = param + (start_index, page_size)
result = self.execute(sql, param)
if not result:
return [], []
result_data = (self.get_msg_detail(row, my_talker=my_talker) for row in result)
rdata = list(result_data) # 转为列表
wxid_list = {d['talker'] for d in rdata} # 创建一个无重复的 wxid 列表
return rdata, list(wxid_list)
@db_error
def get_date_count(self, wxid='', start_time: int = 0, end_time: int = 0, time_format='%Y-%m-%d'):
"""
获取每日聊天记录数量,包括发送者数量、接收者数量和总数。
"""
if not self.tables_exist("MSG"):
return {}
if isinstance(start_time, str) and start_time.isdigit():
start_time = int(start_time)
if isinstance(end_time, str) and end_time.isdigit():
end_time = int(end_time)
# if start_time or end_time is not an integer and not a float, set both to 0
if not (isinstance(start_time, (int, float)) and isinstance(end_time, (int, float))):
start_time = 0
end_time = 0
params = ()
sql_wxid = "AND StrTalker = ? " if wxid else ""
params = params + (wxid,) if wxid else params
sql_time = "AND CreateTime BETWEEN ? AND ? " if start_time and end_time else ""
params = params + (start_time, end_time) if start_time and end_time else params
sql = (f"SELECT strftime('{time_format}', CreateTime, 'unixepoch', 'localtime') AS date, "
" COUNT(*) AS total_count ,"
" SUM(CASE WHEN IsSender = 1 THEN 1 ELSE 0 END) AS sender_count, "
" SUM(CASE WHEN IsSender = 0 THEN 1 ELSE 0 END) AS receiver_count "
"FROM MSG "
"WHERE StrTalker NOT LIKE '%chatroom%' "
f"{sql_wxid} {sql_time} "
f"GROUP BY date ORDER BY date ASC;")
result = self.execute(sql, params)
if not result:
return {}
# 将查询结果转换为字典
result_dict = {}
for row in result:
date, total_count, sender_count, receiver_count = row
result_dict[date] = {
"sender_count": sender_count,
"receiver_count": receiver_count,
"total_count": total_count
}
return result_dict
@db_error
def get_top_talker_count(self, top: int = 10, start_time: int = 0, end_time: int = 0):
"""
获取聊天记录数量最多的联系人,他们聊天记录数量
"""
if not self.tables_exist("MSG"):
return {}
if isinstance(start_time, str) and start_time.isdigit():
start_time = int(start_time)
if isinstance(end_time, str) and end_time.isdigit():
end_time = int(end_time)
# if start_time or end_time is not an integer and not a float, set both to 0
if not (isinstance(start_time, (int, float)) and isinstance(end_time, (int, float))):
start_time = 0
end_time = 0
sql_time = f"AND CreateTime BETWEEN {start_time} AND {end_time} " if start_time and end_time else ""
sql = (
"SELECT StrTalker, COUNT(*) AS count,"
"SUM(CASE WHEN IsSender = 1 THEN 1 ELSE 0 END) AS sender_count, "
"SUM(CASE WHEN IsSender = 0 THEN 1 ELSE 0 END) AS receiver_count "
"FROM MSG "
"WHERE StrTalker NOT LIKE '%chatroom%' "
f"{sql_time} "
"GROUP BY StrTalker ORDER BY count DESC "
f"LIMIT {top};"
)
result = self.execute(sql)
if not result:
return {}
# 将查询结果转换为字典
result_dict = {row[0]: {"total_count": row[1], "sender_count": row[2], "receiver_count": row[3]} for row in
result}
return result_dict
# 单条消息处理
@db_error
def get_msg_detail(self, row, my_talker="我"):
"""
获取单条消息详情,格式化输出
"""
(localId, TalkerId, MsgSvrID, Type, SubType, CreateTime, IsSender, Sequence, StatusEx, FlagEx, Status,
MsgSequence, StrContent, MsgServerSeq, StrTalker, DisplayContent, Reserved0, Reserved1, Reserved3,
Reserved4, Reserved5, Reserved6, CompressContent, BytesExtra, BytesTrans, Reserved2, _id) = row
CreateTime = timestamp2str(CreateTime)
type_id = (Type, SubType)
type_name = type_converter(type_id)
msg = StrContent
src = ""
extra = {}
if type_id == (1, 0): # 文本
msg = StrContent
elif type_id == (3, 0): # 图片
DictExtra = get_BytesExtra(BytesExtra)
DictExtra_str = str(DictExtra)
img_paths = [i for i in re.findall(r"(FileStorage.*?)'", DictExtra_str)]
img_paths = sorted(img_paths, key=lambda p: "Image" in p, reverse=True)
if img_paths:
img_path = img_paths[0].replace("'", "")
img_path = [i for i in img_path.split("\\") if i]
img_path = os.path.join(*img_path)
src = img_path
else:
src = ""
msg = "图片"
elif type_id == (34, 0): # 语音
tmp_c = xml2dict(StrContent)
voicelength = tmp_c.get("voicemsg", {}).get("voicelength", "")
transtext = tmp_c.get("voicetrans", {}).get("transtext", "")
if voicelength.isdigit():
voicelength = int(voicelength) / 1000
voicelength = f"{voicelength:.2f}"
msg = f"语音时长:{voicelength}秒\n翻译结果:{transtext}" if transtext else f"语音时长:{voicelength}秒"
src = os.path.join(f"{StrTalker}",
f"{CreateTime.replace(':', '-').replace(' ', '_')}_{IsSender}_{MsgSvrID}.wav")
elif type_id == (43, 0): # 视频
DictExtra = get_BytesExtra(BytesExtra)
DictExtra = str(DictExtra)
DictExtra_str = str(DictExtra)
video_paths = [i for i in re.findall(r"(FileStorage.*?)'", DictExtra_str)]
video_paths = sorted(video_paths, key=lambda p: "mp4" in p, reverse=True)
if video_paths:
video_path = video_paths[0].replace("'", "")
video_path = [i for i in video_path.split("\\") if i]
video_path = os.path.join(*video_path)
src = video_path
else:
src = ""
msg = "视频"
elif type_id == (47, 0): # 动画表情
content_tmp = xml2dict(StrContent)
cdnurl = content_tmp.get("emoji", {}).get("cdnurl", "")
if not cdnurl:
DictExtra = get_BytesExtra(BytesExtra)
cdnurl = match_BytesExtra(DictExtra)
if cdnurl:
msg, src = "表情", cdnurl
elif type_id == (48, 0): # 地图信息
content_tmp = xml2dict(StrContent)
location = content_tmp.get("location", {})
msg = (f"纬度:【{location.pop('x')}】 经度:【{location.pop('y')}】\n"
f"位置:{location.pop('label')} {location.pop('poiname')}\n"
f"其他信息:{json.dumps(location, ensure_ascii=False, indent=4)}"
)
src = ""
elif type_id == (49, 0): # 文件
DictExtra = get_BytesExtra(BytesExtra)
url = match_BytesExtra(DictExtra)
src = url
file_name = os.path.basename(url)
msg = file_name
elif type_id == (49, 5): # (分享)卡片式链接
CompressContent = decompress_CompressContent(CompressContent)
CompressContent_tmp = xml2dict(CompressContent)
appmsg = CompressContent_tmp.get("appmsg", {})
title = appmsg.get("title", "")
des = appmsg.get("des", "")
url = appmsg.get("url", "")
msg = f'{title}\n{des}\n\n<a href="{url}" target="_blank">点击查看详情</a>'
src = url
extra = appmsg
elif type_id == (49, 19): # 合并转发的聊天记录
CompressContent = decompress_CompressContent(CompressContent)
content_tmp = xml2dict(CompressContent)
title = content_tmp.get("appmsg", {}).get("title", "")
des = content_tmp.get("appmsg", {}).get("des", "")
recorditem = content_tmp.get("appmsg", {}).get("recorditem", "")
recorditem = xml2dict(recorditem)
msg = f"{title}\n{des}"
src = recorditem
elif type_id == (49, 57): # 带有引用的文本消息
CompressContent = decompress_CompressContent(CompressContent)
content_tmp = xml2dict(CompressContent)
appmsg = content_tmp.get("appmsg", {})
title = appmsg.get("title", "")
refermsg = appmsg.get("refermsg", {})
type_id = appmsg.get("type", "1")
displayname = refermsg.get("displayname", "")
display_content = refermsg.get("content", "")
display_createtime = refermsg.get("createtime", "")
display_createtime = timestamp2str(
int(display_createtime)) if display_createtime.isdigit() else display_createtime
if display_content and display_content.startswith("<?xml"):
display_content = xml2dict(display_content)
if "img" in display_content:
display_content = "图片"
else:
appmsg1 = display_content.get("appmsg", {})
title1 = appmsg1.get("title", "")
display_content = title1 if title1 else display_content
msg = f"{title}\n\n[引用]({display_createtime}){displayname}:{display_content}"
src = ""
elif type_id == (49, 2000): # 转账消息
CompressContent = decompress_CompressContent(CompressContent)
content_tmp = xml2dict(CompressContent)
wcpayinfo = content_tmp.get("appmsg", {}).get("wcpayinfo", {})
paysubtype = wcpayinfo.get("paysubtype", "") # 转账类型
feedesc = wcpayinfo.get("feedesc", "") # 转账金额
pay_memo = wcpayinfo.get("pay_memo", "") # 转账备注
begintransfertime = wcpayinfo.get("begintransfertime", "") # 转账开始时间
msg = (f"{'已收款' if paysubtype == '3' else '转账'}:{feedesc}\n"
f"转账说明:{pay_memo if pay_memo else ''}\n"
f"转账时间:{timestamp2str(begintransfertime)}\n"
)
src = ""
elif type_id[0] == 49 and type_id[1] != 0:
DictExtra = get_BytesExtra(BytesExtra)
url = match_BytesExtra(DictExtra)
src = url
msg = type_name
elif type_id == (50, 0): # 语音通话
msg = "语音/视频通话[%s]" % DisplayContent
# elif type_id == (10000, 0):
# msg = StrContent
# elif type_id == (10000, 4):
# msg = StrContent
# elif type_id == (10000, 8000):
# msg = StrContent
talker = "未知"
if IsSender == 1:
talker = my_talker
else:
if StrTalker.endswith("@chatroom"):
bytes_extra = get_BytesExtra(BytesExtra)
if bytes_extra:
try:
talker = bytes_extra['3'][0]['2']
if "publisher-id" in talker:
talker = "系统"
except:
pass
else:
talker = StrTalker
row_data = {"id": _id, "MsgSvrID": str(MsgSvrID), "type_name": type_name, "is_sender": IsSender,
"talker": talker, "room_name": StrTalker, "msg": msg, "src": src, "extra": extra,
"CreateTime": CreateTime, }
return row_data
@db_error
def decompress_CompressContent(data):
"""
解压缩Msg:CompressContent内容
:param data: CompressContent内容 bytes
:return:
"""
if data is None or not isinstance(data, bytes):
return None
try:
dst = lz4.block.decompress(data, uncompressed_size=len(data) << 8)
dst = dst.replace(b'\x00', b'') # 已经解码完成后,还含有0x00的部分,要删掉,要不后面ET识别的时候会报错
uncompressed_data = dst.decode('utf-8', errors='ignore')
return uncompressed_data
except Exception as e:
return data.decode('utf-8', errors='ignore')
@db_error
def get_BytesExtra(BytesExtra):
BytesExtra_message_type = {
"1": {
"type": "message",
"message_typedef": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "int",
"name": ""
}
},
"name": "1"
},
"3": {
"type": "message",
"message_typedef": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "str",
"name": ""
}
},
"name": "3",
"alt_typedefs": {
"1": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {},
"name": ""
}
},
"2": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"13": {
"type": "fixed32",
"name": ""
},
"12": {
"type": "fixed32",
"name": ""
}
},
"name": ""
}
},
"3": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"15": {
"type": "fixed64",
"name": ""
}
},
"name": ""
}
},
"4": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"15": {
"type": "int",
"name": ""
},
"14": {
"type": "fixed32",
"name": ""
}
},
"name": ""
}
},
"5": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"12": {
"type": "fixed32",
"name": ""
},
"7": {
"type": "fixed64",
"name": ""
},
"6": {
"type": "fixed64",
"name": ""
}
},
"name": ""
}
},
"6": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"7": {
"type": "fixed64",
"name": ""
},
"6": {
"type": "fixed32",
"name": ""
}
},
"name": ""
}
},
"7": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"12": {
"type": "fixed64",
"name": ""
}
},
"name": ""
}
},
"8": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"6": {
"type": "fixed64",
"name": ""
},
"12": {
"type": "fixed32",
"name": ""
}
},
"name": ""
}
},
"9": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"15": {
"type": "int",
"name": ""
},
"12": {
"type": "fixed64",
"name": ""
},
"6": {
"type": "int",
"name": ""
}
},
"name": ""
}
},
"10": {
"1": {
"type": "int",
"name": ""
},
"2": {
"type": "message",
"message_typedef": {
"6": {
"type": "fixed32",
"name": ""
},
"12": {
"type": "fixed64",
"name": ""
}
},
"name": ""
}
},
}
}
}
if BytesExtra is None or not isinstance(BytesExtra, bytes):
return None
try:
deserialize_data, message_type = blackboxprotobuf.decode_message(BytesExtra, BytesExtra_message_type)
return deserialize_data
except Exception as e:
return None
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: OpenIMContact.py
# Description:
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
from .dbbase import DatabaseBase
from .utils import db_error
class OpenIMContactHandler(DatabaseBase):
_class_name = "OpenIMContact"
OpenIMContact_required_tables = ["OpenIMContact"]
def get_im_user_list(self, word=None, wxids=None):
"""
获取联系人列表
[ 注意:如果修改这个函数,要同时修改dbMicro.py中的get_user_list函数 ]
:param word: 查询关键字,可以是用户名、昵称、备注、描述,允许拼音
:param wxids: 微信id列表
:return: 联系人字典
"""
if not self.tables_exist("OpenIMContact"):
return []
if not wxids:
wxids = {}
if isinstance(wxids, str):
wxids = [wxids]
sql = ("SELECT UserName,NickName,Type,Remark,BigHeadImgUrl,CustomInfoDetail,CustomInfoDetailVisible,"
"AntiSpamTicket,AppId,Sex,DescWordingId,ExtraBuf "
"FROM OpenIMContact WHERE 1==1 ;")
if word:
sql = sql.replace(";",
f"AND (UserName LIKE '%{word}%' "
f"OR NickName LIKE '%{word}%' "
f"OR Remark LIKE '%{word}%' "
f"OR LOWER(NickNamePYInit) LIKE LOWER('%{word}%') "
f"OR LOWER(NickNameQuanPin) LIKE LOWER('%{word}%') "
f"OR LOWER(RemarkPYInit) LIKE LOWER('%{word}%') "
f"OR LOWER(RemarkQuanPin) LIKE LOWER('%{word}%') "
") ;")
if wxids:
sql = sql.replace(";", f"AND UserName IN ('" + "','".join(wxids) + "') ;")
result = self.execute(sql)
if not result:
return {}
users = {}
for row in result:
# 获取用户名、昵称、备注和聊天记录数量
(UserName, NickName, Type, Remark, BigHeadImgUrl, CustomInfoDetail, CustomInfoDetailVisible,
AntiSpamTicket, AppId, Sex, DescWordingId, ExtraBuf) = row
users[UserName] = {
"wxid": UserName, "nickname": NickName, "remark": Remark, "account": UserName,
"describe": '', "headImgUrl": BigHeadImgUrl if BigHeadImgUrl else "",
"ExtraBuf": None, "LabelIDList": tuple(), "extra": None}
return users
@db_error
def get_ExtraBuf(ExtraBuf: bytes):
"""
读取ExtraBuf(联系人表)
:param ExtraBuf:
:return:
"""
if not ExtraBuf:
return None
buf_dict = {
'74752C06': '性别[1男2女]', '46CF10C4': '个性签名', 'A4D9024A': '国', 'E2EAA8D1': '省', '1D025BBF': '市',
'F917BCC0': '公司名称', '759378AD': '手机号', '4EB96D85': '企微属性', '81AE19B4': '朋友圈背景',
'0E719F13': '备注图片', '945f3190': '备注图片2',
'DDF32683': '0', '88E28FCE': '1', '761A1D2D': '2', '0263A0CB': '3', '0451FF12': '4', '228C66A8': '5',
'4D6C4570': '6', '4335DFDD': '7', 'DE4CDAEB': '8', 'A72BC20A': '9', '069FED52': '10', '9B0F4299': '11',
'3D641E22': '12', '1249822C': '13', 'B4F73ACB': '14', '0959EB92': '15', '3CF4A315': '16',
'C9477AC60201E44CD0E8': '17', 'B7ACF0F5': '18', '57A7B5A8': '19', '695F3170': '20', 'FB083DD9': '21',
'0240E37F': '22', '315D02A3': '23', '7DEC0BC3': '24', '16791C90': '25'
}
rdata = {}
for buf_name in buf_dict:
rdata_name = buf_dict[buf_name]
buf_name = bytes.fromhex(buf_name)
offset = ExtraBuf.find(buf_name)
if offset == -1:
rdata[rdata_name] = ""
continue
offset += len(buf_name)
type_id = ExtraBuf[offset: offset + 1]
offset += 1
if type_id == b"\x04":
rdata[rdata_name] = int.from_bytes(ExtraBuf[offset: offset + 4], "little")
elif type_id == b"\x18":
length = int.from_bytes(ExtraBuf[offset: offset + 4], "little")
rdata[rdata_name] = ExtraBuf[offset + 4: offset + 4 + length].decode("utf-16").rstrip("\x00")
elif type_id == b"\x17":
length = int.from_bytes(ExtraBuf[offset: offset + 4], "little")
rdata[rdata_name] = ExtraBuf[offset + 4: offset + 4 + length].decode("utf-8", errors="ignore").rstrip(
"\x00")
elif type_id == b"\x05":
rdata[rdata_name] = f"0x{ExtraBuf[offset: offset + 8].hex()}"
return rdata
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: OpenIMMedia.py
# Description: 负责处理语音数据库
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
from .dbbase import DatabaseBase
from .utils import silk2audio, db_loger
class OpenIMMediaHandler(DatabaseBase):
_class_name = "OpenIMMedia"
OpenIMMedia_required_tables = ["OpenIMMedia"]
def get_im_audio(self, MsgSvrID, is_play=False, is_wave=False, save_path=None, rate=24000):
if not self.tables_exist("OpenIMMedia"):
return False
sql = "select Buf from OpenIMMedia where Reserved0=? "
DBdata = self.execute(sql, (MsgSvrID,))
if not DBdata:
return False
if len(DBdata) == 0:
return False
data = DBdata[0][0] # [1:] + b'\xFF\xFF'
try:
pcm_data = silk2audio(buf_data=data, is_play=is_play, is_wave=is_wave, save_path=save_path, rate=rate)
return pcm_data
except Exception as e:
db_loger.warning(e, exc_info=True)
return False
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: PublicMsg.py
# Description: 负责处理公众号数据库信息
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
from .dbMSG import MsgHandler
from .utils import db_error
class PublicMsgHandler(MsgHandler):
_class_name = "PublicMSG"
PublicMSG_required_tables = ["PublicMsg"]
def PublicMsg_add_index(self):
"""
添加索引,加快查询速度
"""
# 检查是否存在索引
if not self.tables_exist("PublicMsg"):
return
sql = "CREATE INDEX IF NOT EXISTS idx_PublicMsg_StrTalker ON PublicMsg(StrTalker);"
self.execute(sql)
sql = "CREATE INDEX IF NOT EXISTS idx_PublicMsg_CreateTime ON PublicMsg(CreateTime);"
self.execute(sql)
sql = "CREATE INDEX IF NOT EXISTS idx_PublicMsg_StrTalker_CreateTime ON PublicMsg(StrTalker, CreateTime);"
self.execute(sql)
@db_error
def get_plc_msg_count(self, wxids: list = ""):
"""
获取聊天记录数量,根据wxid获取单个联系人的聊天记录数量,不传wxid则获取所有联系人的聊天记录数量
:param wxids: wxid list
:return: 聊天记录数量列表 {wxid: chat_count}
"""
if not self.tables_exist("PublicMsg"):
return {}
if isinstance(wxids, str) and wxids:
wxids = [wxids]
if wxids:
wxids = "('" + "','".join(wxids) + "')"
sql = f"SELECT StrTalker, COUNT(*) FROM PublicMsg WHERE StrTalker IN {wxids} GROUP BY StrTalker ORDER BY COUNT(*) DESC;"
else:
sql = f"SELECT StrTalker, COUNT(*) FROM PublicMsg GROUP BY StrTalker ORDER BY COUNT(*) DESC;"
sql_total = f"SELECT COUNT(*) FROM MSG;"
result = self.execute(sql)
total_ret = self.execute(sql_total)
if not result:
return {}
total = 0
if total_ret and len(total_ret) > 0:
total = total_ret[0][0]
msg_count = {"total": total}
msg_count.update({row[0]: row[1] for row in result})
return msg_count
@db_error
def get_plc_msg_list(self, wxids: list or str = "", start_index=0, page_size=500, msg_type: str = "",
msg_sub_type: str = "", start_createtime=None, end_createtime=None, my_talker="我"):
"""
获取聊天记录列表
:param wxids: [wxid]
:param start_index: 起始索引
:param page_size: 页大小
:param msg_type: 消息类型
:param msg_sub_type: 消息子类型
:param start_createtime: 开始时间
:param end_createtime: 结束时间
:return: 聊天记录列表 {"id": _id, "MsgSvrID": str(MsgSvrID), "type_name": type_name, "is_sender": IsSender,
"talker": talker, "room_name": StrTalker, "msg": msg, "src": src, "extra": {},
"CreateTime": CreateTime, }
"""
if not self.tables_exist("PublicMsg"):
return [], []
if isinstance(wxids, str) and wxids:
wxids = [wxids]
param = ()
sql_wxid, param = (f"AND StrTalker in ({', '.join('?' for _ in wxids)}) ",
param + tuple(wxids)) if wxids else ("", param)
sql_type, param = ("AND Type=? ", param + (msg_type,)) if msg_type else ("", param)
sql_sub_type, param = ("AND SubType=? ", param + (msg_sub_type,)) if msg_type and msg_sub_type else ("", param)
sql_start_createtime, param = ("AND CreateTime>=? ", param + (start_createtime,)) if start_createtime else (
"", param)
sql_end_createtime, param = ("AND CreateTime<=? ", param + (end_createtime,)) if end_createtime else ("", param)
sql = (
"SELECT localId,TalkerId,MsgSvrID,Type,SubType,CreateTime,IsSender,Sequence,StatusEx,FlagEx,Status,"
"MsgSequence,StrContent,MsgServerSeq,StrTalker,DisplayContent,Reserved0,Reserved1,Reserved3,"
"Reserved4,Reserved5,Reserved6,CompressContent,BytesExtra,BytesTrans,Reserved2,"
"ROW_NUMBER() OVER (ORDER BY CreateTime ASC) AS id "
"FROM PublicMsg WHERE 1=1 "
f"{sql_wxid}"
f"{sql_type}"
f"{sql_sub_type}"
f"{sql_start_createtime}"
f"{sql_end_createtime}"
f"ORDER BY CreateTime ASC LIMIT ?,?"
)
param = param + (start_index, page_size)
result = self.execute(sql, param)
if not result:
return [], []
result_data = (self.get_msg_detail(row, my_talker=my_talker) for row in result)
rdata = list(result_data) # 转为列表
wxid_list = {d['talker'] for d in rdata} # 创建一个无重复的 wxid 列表
return rdata, list(wxid_list)
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: Sns.py
# Description: 负责处理朋友圈相关数据 软件只能看到在电脑微信浏览过的朋友圈记录
# Author: Rainbow
# Date: 2024/11/08
# -------------------------------------------------------------------------------
import json
from .dbbase import DatabaseBase
from .utils import silk2audio, xml2dict, timestamp2str
# FeedsV20:朋友圈的XML数据
# CommentV20:朋友圈点赞或评论记录
# NotificationV7:朋友圈通知
# SnsConfigV20:一些配置信息,能读懂的是其中有你的朋友圈背景图
# SnsGroupInfoV5:猜测是旧版微信朋友圈可见范围的可见或不可见名单
class SnsHandler(DatabaseBase):
_class_name = "Sns"
Media_required_tables = ["AdFeedsV8", "FeedsV20", "CommentV20", "NotificationV7", "SnsConfigV20", "SnsFailureV5",
"SnsGroupInfoV5", "SnsNoNotifyV5"]
def get_sns_feed(self):
"""
获取朋友圈数据
http://shmmsns.qpic.cn/mmsns/uGxMq1C4wvppcjBbyweK796GtT1hH3LGISYajZ2v7C11XhHk5icyDUXcWNSPk2MooeIa8Es5hXP0/0?idx=1&token=WSEN6qDsKwV8A02w3onOGQYfxnkibdqSOkmHhZGNB4DFumlE9p1vp0e0xjHoXlbbXRzwnQia6X5t3Annc4oqTuDg
"""
sql = (
"SELECT FeedId, CreateTime, FaultId, Type, UserName, Status, ExtFlag, PrivFlag, StringId, Content "
"FROM FeedsV20 "
"ORDER BY CreateTime DESC")
FeedsV20 = self.execute(sql)
for row in FeedsV20[2:]:
(FeedId, CreateTime, FaultId, Type, UserName, Status, ExtFlag, PrivFlag, StringId, Content) = row
Content = xml2dict(Content) if Content and Content.startswith("<") else Content
CreateTime = timestamp2str(CreateTime)
print(
f"{FeedId=}\n"
f"{CreateTime=}\n"
f"{FaultId=}\n"
f"{Type=}\n"
f"{UserName=}\n"
f"{Status=}\n"
f"{ExtFlag=}\n"
f"{PrivFlag=}\n"
f"{StringId=}\n\n"
f"{json.dumps(Content, indent=4, ensure_ascii=False)}\n\n"
)
return FeedId, CreateTime, FaultId, Type, UserName, Status, ExtFlag, PrivFlag, StringId, Content
def get_sns_comment(self):
pass
 官方公众号
官方公众号