ETJava Beta | Java
 注册
登录
注册
登录
注册
登录
注册
登录
在创建索引时 IndexWriterConfig对象中默认使用的是标准分析器(StandardAnalyzer)
最终需要在分析器中对数据内容进行分词
1. 查看标准分析器的分析效果
使用Analyzer对象的tokenStream方法,该方法返回一个TokenStream对象,该对象包含了最终的分词结果
实现步骤:
1. 创建Analyzer对象 使用标准分析器 StandardAnalyzer
2. 调用分析器对象的tokenStream方法 获取TokenStream对象
3. 向TokenStream对象中设置一个引用 相当于结果集中的指针
4. 调用TokenStream对象中的reset方法 将指针重置 ,不调用会抛出异常
5. 循环遍历TokenStream对象,该对象包含了最终的分析分词结果
6. 关闭TokenStream对象
* 7.x 之前的版本是将is a and 等这类词直接去除,8.0开始 这类词也都会保存
package com.et.lucene01;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import java.io.IOException;
/**
* @Author: ETJAVA
* @CreateTime: 2024-04-05 12:33
* @Description: TODO 查看分析器的分词效果
* @Version: 1.0
*/
public class AnalyzerTokenStream {
public static void main(String[] args) throws IOException {
//1. 创建Analyzer对象 使用标准分析器 StandardAnalyzer
Analyzer analyzer = new StandardAnalyzer();
//2. 调用分析器对象的tokenStream方法 获取TokenStream对象 参数1 域名称,参数2 需要分析的内容
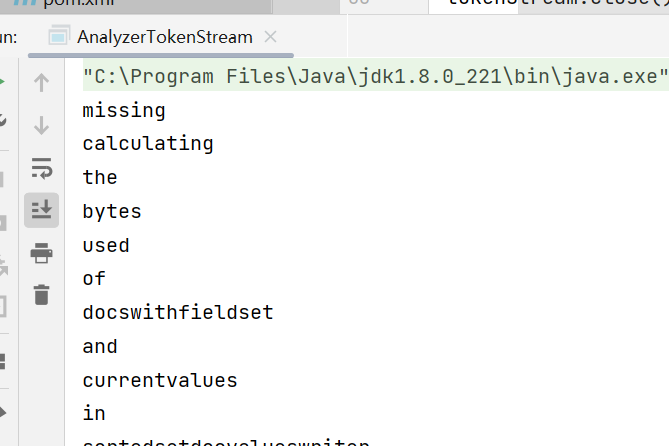
String s = "Missing calculating the bytes used of DocsWithFieldSet and currentValues in SortedSetDocValuesWriter.";
TokenStream tokenStream = analyzer.tokenStream("", s);
//3. 向TokenStream对象中设置一个引用 相当于结果集中的指针
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//4. 调用TokenStream对象中的reset方法 将指针重置 ,不调用会抛出异常
tokenStream.reset();
//5. 循环遍历TokenStream对象,该对象包含了最终的分析分词结果
while(tokenStream.incrementToken()){
System.out.println(charTermAttribute.toString());
}
//6. 关闭TokenStream对象
tokenStream.close();
}
}
 官方公众号
官方公众号
